tdynam(liste_ed)![]()
![]()
1 Présentation du Mobiliscope
1.1 Genèse
Le Mobiliscope a initialement été développé afin de proposer une visualisation interactive des cartes et graphiques de la ségrégation heure par heure des groupes sociaux dans l’agglomération parisienne. Suite à l’article de Guillaume Le Roux, Julie Vallée et Hadrien Commenges publié en 2017 dans la revue Journal of Transport Geography, l’idée était en effet de développer une interface cartographique interactive librement et gratuitement disponible permettant de :
- présenter les cartes et graphiques de façon plus exhaustive que dans l’article scientifique ;
- donner accès à des informations détaillées sur la population présente dans chacun des secteurs au cours des 24 heures de la journée ;
- faciliter la comparaison entre les indicateurs, les modalités, les heures et les secteurs ;
- proposer une interface libre et grand public valorisant les analyses sur les inégalités sociales au-delà du seul milieu académique.
La première version du Mobiliscope portait ainsi uniquement sur l’Île-de-France selon deux indicateurs sociaux (niveau d’éducation et CSP). Les versions ultérieures du Mobiliscope ont été enrichies de nouveaux indicateurs et ont été étendues à d’autres villes (françaises mais aussi étrangères) disposant d’enquêtes représentatives sur les déplacements quotidiens de populations. L’outil Mobiliscope s’est aussi progressivement étoffé : en plus de l’interface de géovisualisation proprement dite, il comporte désormais une page d’accueil et de nombreuses pages d’information et de documentation. L’interface est aussi maintenant trilingue (français, anglais et espagnol).
L’extension du Mobiliscope s’est fait en plusieurs temps. Les deux premières versions de l’outil, centrées sur l’Île-de-France, avec une interface en anglais ont été développées durant l’année 2017 (mise en ligne le 24 mai 2017 de la v1 ; mise en ligne de la deuxième version (v2) en septembre 2017). La troisième version du Mobiliscope (v3), développée entre mars 2018 et avril 2020, intégrait 28 nouvelles “villes” françaises et son interface a été traduite en français. La quatrième version (v4) a été l’objet d’une importante refonte de l’interface graphique. De nouvelles enquêtes, indicateurs et fonctionnalités sont ajoutées comme la possibilité pour l’utilisateur de télécharger les données agrégées visualisées dans l’outil. Le détail des évolutions sont consultables dans la page « un outil en évolution ».
Depuis le début, le développement du Mobiliscope a été réalisé par des géomaticiennes (Constance Lecomte, Élisa Villard, puis pendant 4 ans par Aurélie Douet), sous l’impulsion et la coordination scientifique de Julie Vallée, géographe au CNRS (UMR Géographie-cités). Deux autres géographes sont également impliqués dans le projet : Guillaume Le Roux sur les questions des inégalités socio-spatiales (Île-de-France, Amérique latine) ainsi qu’Hadrien Commenges. Si le traitement et la représentation de l’information géographique sont au cœur du projet, l’outil s’appuie également sur d’autres compétences. Ainsi, le Mobiliscope bénéficie régulièrement depuis 2019 de l’expérience web de Renaud Bessières de l’agence qodop. Plus récemment, Mathieu Leclaire est venu consolider le volet informatique du projet (machine virtuelle mise à disposition par Huma-Num, stockage des données sur l’interface MinIO, développement de l’outil Mobiliquest…).
1.2 Guide Admin
Ce Guide Administrateur·rice a pour objectif de présenter le Mobiliscope dans sa version 4.3 afin :
- d’en connaître le fonctionnement précis ;
- de le maintenir en état ;
- d’effectuer des mises à jour ;
- de poursuivre son développement.
Ce Guide est publié ici : mobiliscope.quarto.pub/guide_admin/guide_admin.html
- Pour modifier ce guide : data-process/guide_admin.qmd
- Pour publier une nouvelle version du guide :
Se connecter à quarto depuis l’account mobiliscope@parisgeo.cnrs.fr & password (#PrivateAccess)
Indiquer dans le terminal R
quarto publish quarto-pubRépondre Oui (Y) à la question
update site at https://mobiliscope.quarto.pub/guide_admin? (Y/n)Vérifier que cela est publié dans https://quartopub.com
Remarque : Ce guide étant public, les login/mots de passe en accès privés (#PrivateAccess) sont listés dans un autre document.
1.3 Description du site
Cette section s’attache à décrire les différentes pages existant sur le site internet du Mobiliscope ainsi que les fonctionnalités de la géovisualisation.
Le site internet du Mobiliscope est responsive, consultable sur ordinateur comme sur tablette ou téléphone mobile, à l’adresse www.mobiliscope.cnrs.fr (entre mai 2017 et avril 2021, l’url était www.mobiliscope.parisgeo.cnrs.fr).
1.3.1 La page d’accueil
La page d’accueil contient des éléments de présentation et de nombreux liens pour circuler dans le site. Elle est constituée, de haut en bas

D’un bandeau d’entête (header). Présent sur chacune des pages, il contient toujours les mêmes éléments interactifs
Le logo “MOBILISCOPE” qui renvoie sur la page d’accueil ;
L’icône loupe ( search) qui permet d’effectuer une recherche par communes et d’être redirigé vers la géovisualisation correspondante ;
Un petit menu “langue” (droplang) qui se déploie au survol pour changer la langue sur tout le site ;
Le menu général du site qui s’ouvre au clic pour accéder à l’ensemble des pages d’information et de géovisualisation.
Figure 2: Menu général du site 
D’une page scrolable contenant
Un titre précédé du logo du CNRS et suivi du search déployé.
Une courte présentation suivie de chiffres clés
Trois cartes présentant la localisation des villes à explorer et l’étendue du périmètre des enquêtes. Ces cartes permettent la redirection vers une page de géovisualisation en cliquant sur le point correspondant.
Figure 3: Cartes d’accueil 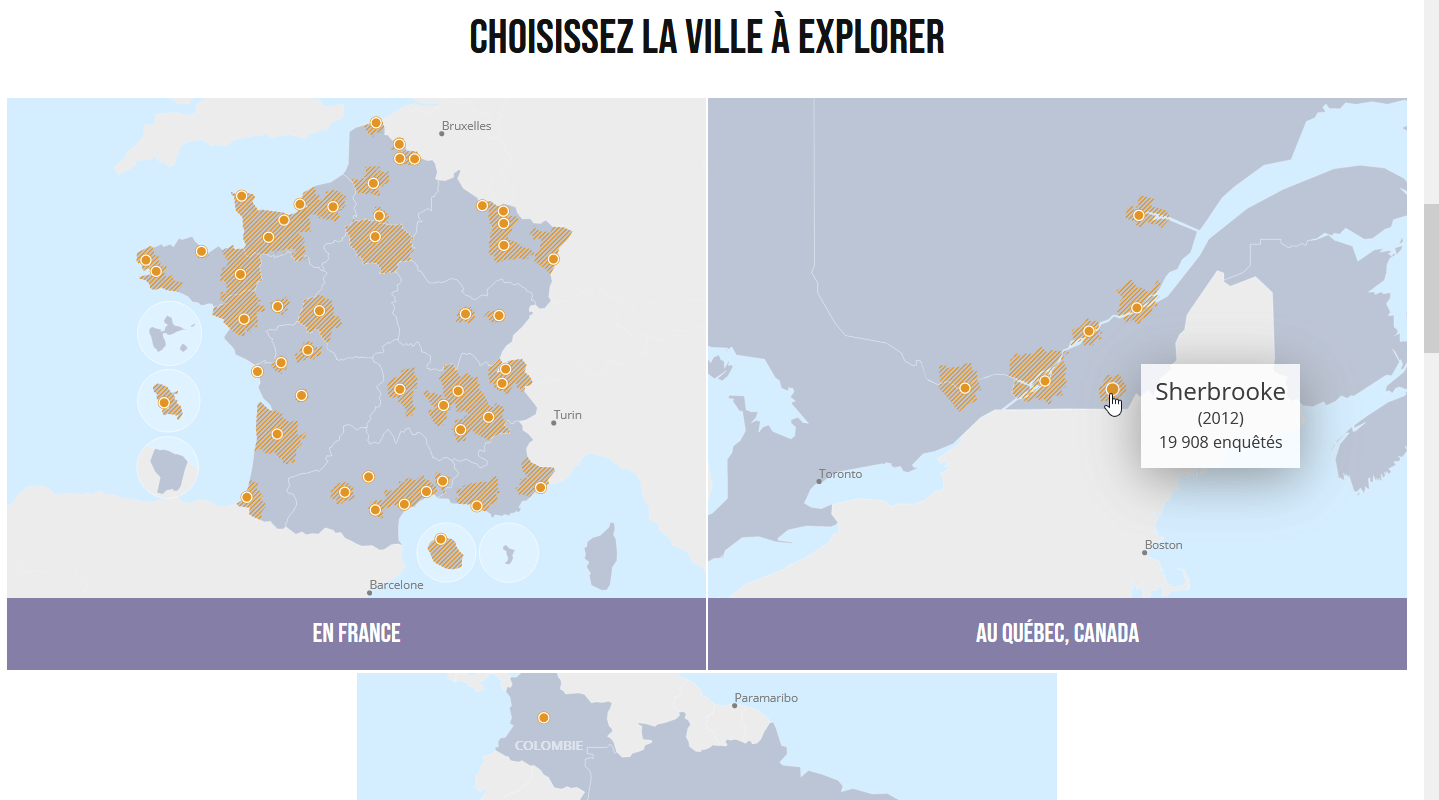
Trois courts témoignages de professionnel·lle·s utilisant le Mobiliscope
De la liste des villes et leur « région » à explorer. Il s’agit de la même information contenue dans les cartes d’accueil et le menu général qui est répétée ici. Les éléments sont cliquables.
Un pied de page (le footer) comportant le logo du CNRS, l’adresse mail du Mobiliscope, un lien vers les dépôts GitLab, Zenodo et le compte Twitter, ainsi que des liens vers certaines des pages d’information du site. Le footer est commun à toutes les pages du site à l’exception des pages de géovisualisation (pas de footer pour ces pages).
1.3.2 Les pages d’information
Les pages d’information sont accessibles à tout moment depuis le menu déroulant situé dans le header. Elles ont été organisées en cinq parties - « A propos », « Méthodes », « Science Ouverte », « Champs d’application » et « Boite à outils » - elles-mêmes déclinées en sous-parties.
Depuis une page d’information, il est possible de naviguer vers les autres pages d’information de plusieurs manières
- en cliquant sur les liens hypertextes (en orange) ;
- en se laissant guider par les boutons de redirection à la fin des paragraphes ;
- en utilisant le menu à plusieurs niveaux situé à gauche des pages d’information ;
- en utilisant le menu général du site.
1.3.3 Les pages de géovisualisation
Pour afficher une page de géovisualisation, trois chemins sont possibles
- Dans le menu général du site, cliquer sur la ville-région choisie
- Via le search, indiquer le nom de la commune recherchée
- Sur les cartes de la page d’accueil, cliquer sur la région choisie
Comme pour ses versions précédentes, l’interface de géovisualisation de la v4.3 se compose de 4 blocs principaux : le menu des indicateurs (1) permet de naviguer entre les indicateurs et leurs modalités et de les afficher sur la carte (2) au centre de la page ; en haut, la timeline permet de naviguer entre les heures (4) ; les graphiques (3) permettent d’afficher des informations sur un secteur en particulier (en haut) et sur la répartition spatiale des groupes sociaux à l’échelle régionale (en bas). Le bloc des graphiques peut être fermé au clic sur la croix pour laisser davantage d’espace à la carte.
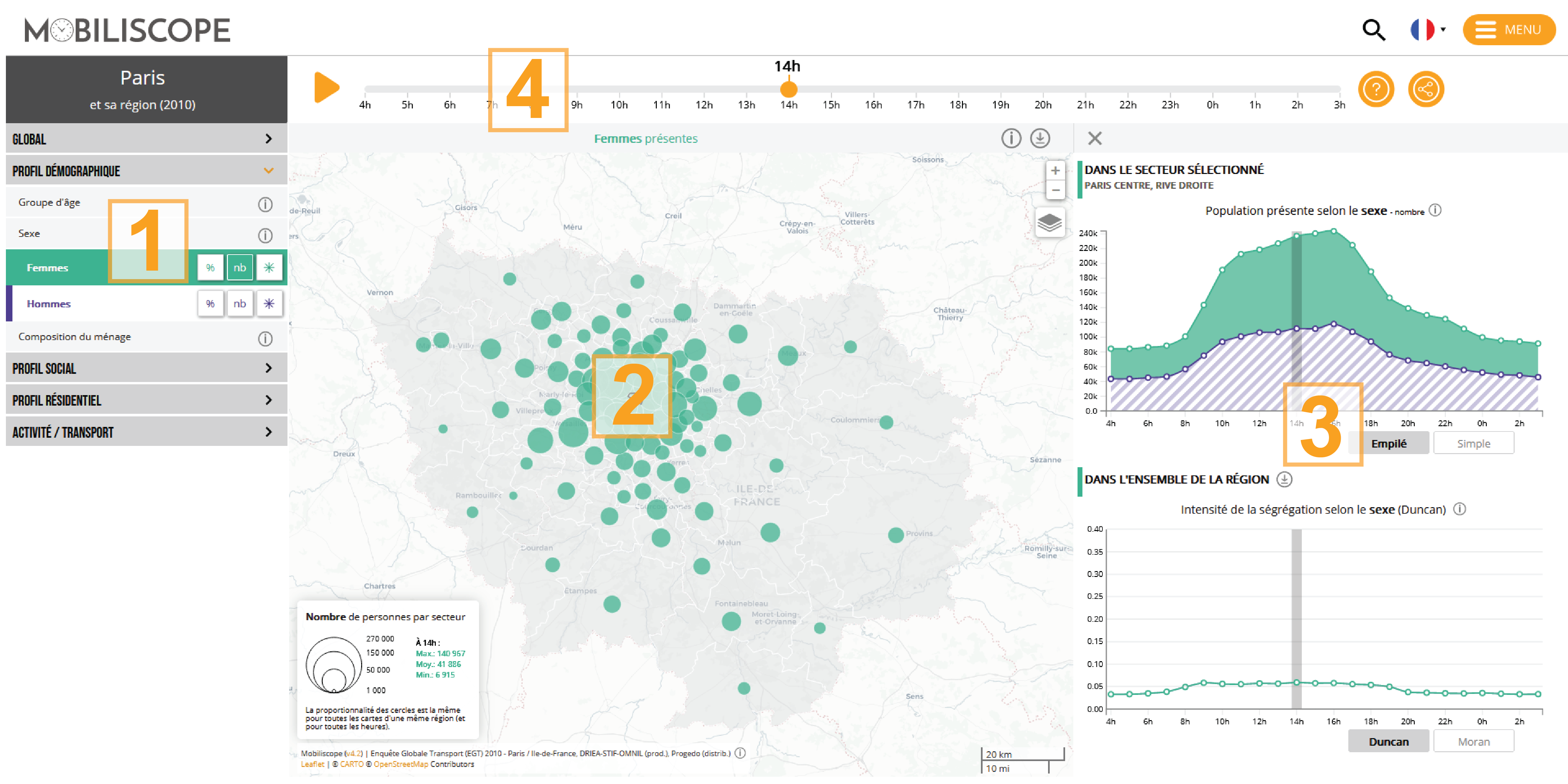
Cette interface est commune aux 58 villes et leur région présentes dans le Mobiliscope. Le titre situé au dessus du menu rappelle l’enquête et le territoire sélectionnés.
En utilisant les liens disponibles dans le header, il est possible de naviguer vers d’autres pages du site.
Aux 58 villes disponibles, s’ajoutent
- l’ancien millésime de Valenciennes et sa région (2011) qui n’est pas référencé mais qui est consultable à cette adresse : https://mobiliscope.cnrs.fr/fr/geoviz/valenciennes2011
- le nouveau millésime pour Paris et sa région (2020) qui n’est pas référencé mais qui est consultable à cette adresse : https://mobiliscope.cnrs.fr/fr/geoviz/idf2020
1.4 Les fonctionnalités de la géovisualisation
Grâce à ses fonctionnalités, le Mobiliscope donne à voir les variations de la composition des populations présentes dans les territoires au cours des 24 heures d’une journée typique de semaine (lundi->vendredi). Les populations sont décrites selon différents indicateurs démographiques et sociaux et sont représentées sur la carte centrale. Les graphiques qui accompagnent la carte permettent d’afficher des informations sur un secteur en particulier (en haut) et sur la répartition spatiale des groupes sociaux à l’échelle de la “région” (en bas).
1.4.1 L’affichage des indicateurs
Par défaut, le Mobiliscope affiche la carte des femmes (en nombre par secteur) à 14h, qui est une modalité de l’indicateur « sexe ». Le nombre d’indicateurs et de modalités varie selon la ville observée. Pour donner un ordre de grandeur, la géovisualisation de l’Île-de-France compte 16 indicateurs et 58 modalités.
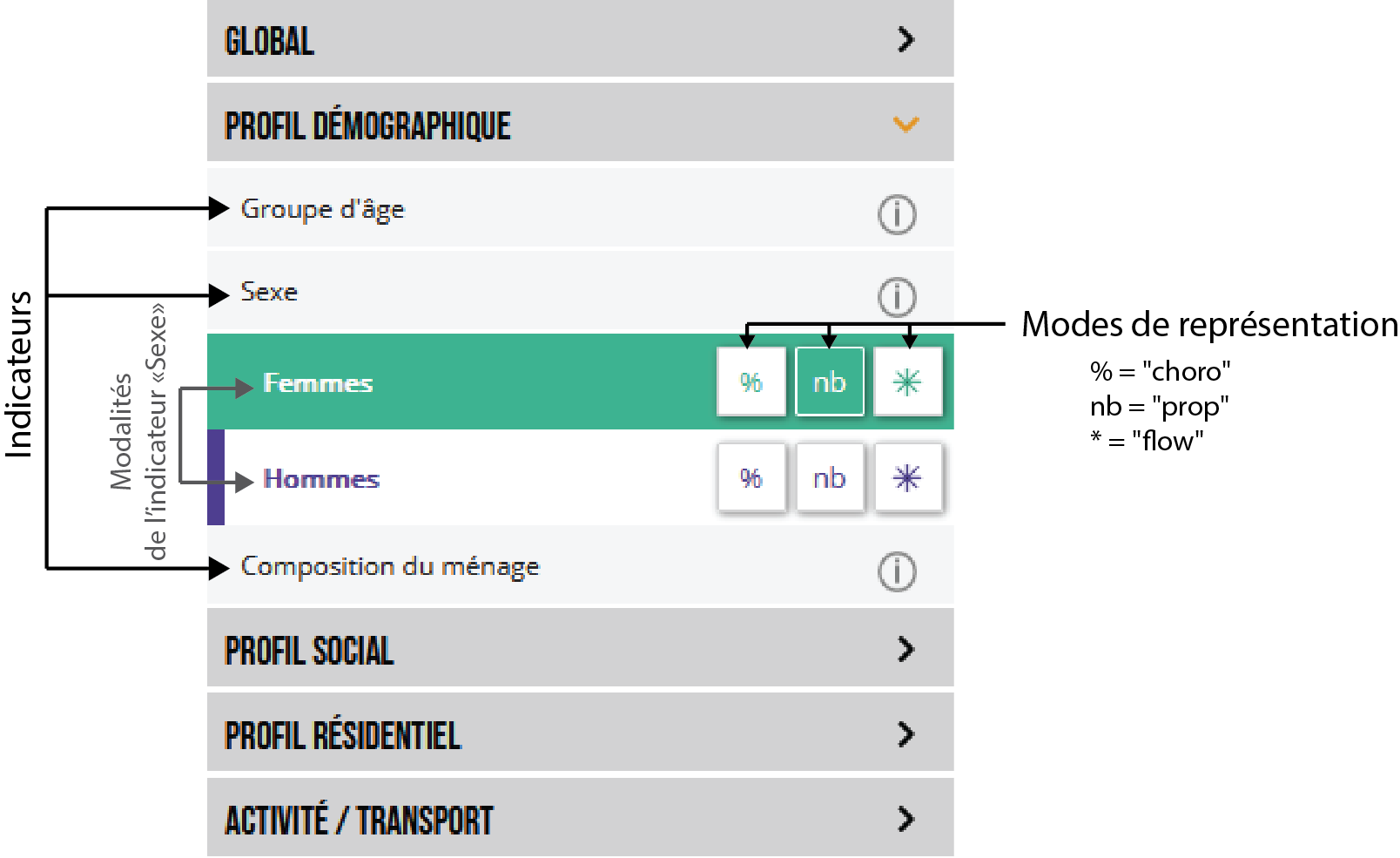
Le menu des indicateurs permet d’afficher les modalités disponibles à l’affichage. Ces informations sont ordonnées selon une architecture multi-niveaux
- niveau 1 : groupe d’indicateurs
- niveau 2 : indicateurs
- niveau 3 : modalités
Un seul indicateur peut être ouvert à la fois.
La répartition spatiale de chaque modalité peut être affichée en proportion dans des cartes choroplèthes (en cliquant sur le bouton « % »), en stock dans des cartes en cercles proportionnels (bouton « nb ») et en nombre de non-résidents avec les principaux flux secteur de présence / secteur de résidence dans des cartes dites en « oursins » (bouton « * »). La modalité correspondant à la carte affichée dans l’interface est surlignée avec la couleur qui lui est propre. À noter : pour la population totale, la carte choroplèthe affiche une densité de population et non un pourcentage.
1.4.2 La carte centrale
La carte centrale est constituée de plusieurs couches d’information géographique qui s’adaptent en fonction de la ville choisie. Celles-ci sont sélectionnables depuis le control layer situé en haut à gauche de la carte

Le fond de carte est constitué de tuiles téléchargées au chargement de la carte via la librairie leaflet.js. Trois fonds de carte sont disponibles
- « Fond de carte simple » : affiché par défaut, il s’agit de tuiles basées sur OpenStreetMap et réalisées par CARTO - « Fond de carte détaillé » : les tuiles standard d’OpenStreetMap
- « Photo. aérienne » : En France, les tuiles raster IGN ; Au Canada et en Amérique du Sud, les tuiles raster ESRI
La « carte Mobiliscope », détaillée plus bas, peut être constituée de plusieurs couches selon le mode de représentation et la nature des données affichés.
- En mode choroplèthe (%)
- polygones des secteurs en aplat de couleur avec interactivité (mouseover, click)
- En cercles proportionnels (nb)
- polygones des secteurs avec interactivité (mouseover, click)
- centroïdes des secteurs en cercles proportionnels
- En cercles proportionnels (*)
- polygones des secteurs avec interactivité (mouseover, click)
- centroïdes des secteurs en cercles proportionnels - et au survol de la souris, lignes reliant les centroïdes pour la représentation des principaux flux
- En mode choroplèthe (%)
Les couches d’habillage varient d’une région à l’autre
Pour les régions françaises
Périmètre des Quartiers Prioritaires en Politique de la Ville - QPV
Zonage en Aires Urbaines (ZAU) simplifié en 5 modalités
Aires d’attraction des Villes (AAV)
Action Coeur de Ville (ACV) pour les régions concernées
Petites Villes de Demain (PVD) pour les régions concernées
Pour les régions sud-américaines
contours des communes
périmètre des couronnes centre/périphérie
Pour Bogotá uniquement : ligne du réseau TransMilenio
Pour les régions canadiennes :
- pas de couche d’habillage
La carte est interactive : elle peut être zoomée (avec la roulette de la souris ou en cliquant sur les boutons +/- en haut à droite du bloc de carte, ou avec deux doigts sur les écrans tactiles) ; on peut s’y déplacer à la souris (ou avec le doigt sur les écrans tactiles) ; le nom des secteurs ainsi que les valeurs de la modalité s’affichent au survol de la souris dans une petite fenêtre en haut à gauche de la carte ; les secteurs sont cliquables : le graphique « secteur » (en haut à droite) se met à jour en fonction du secteur cliqué.
La « carte Mobiliscope » se charge au clic dans le menu des indicateurs et s’adapte à l’information (la modalité) et au mode de représentation choisis par l’utilisateur.
Dans les cartes choroplèthes (où sont représentées les parts estimées de personnes présentes d’un groupe donné dans chaque secteur), la légende est toujours définie par cinq classes. Pour chaque modalité, les bornes des classes demeurent les mêmes pour les 24 heurs de la journée dans une région donnée. Elles sont définies de façon dynamique à l’aide de la librairie geostats.js. La méthode discrétisation est indiquée en légende de carte.
Dans les cartes en cercles proportionnels (qui représentent le nombre estimé de personnes d’un groupe donné présentes dans chaque secteur), la taille des cercles est proportionnelle au stock de personnes présentes dans les secteurs. La proportionnalité est rigoureusement similaire pour toutes les cartes d’une même région et à toute heure (elle peut varier selon la région observée).
Dans les cartes en oursins, des cercles proportionnels représentent par secteur les nombres estimés de personnes présentes qui résident en dehors du secteur. Au survol de la souris, les liens qui apparaissent représentent les flux principaux de personnes entre leur secteur de résidence et le secteur où ils sont présents sans y résider. L’épaisseur des liens est similaire pour toutes les cartes d’une même région et à toute heure (mais peut varier en fonction de la région observée). Pour des questions de confidentialité des données et de représentativité statistique, un filtre a été mis en place dans le script R de préparation des données pour ne faire apparaître que les liens concernant un nombre brut d’enquêtés supérieur ou égal à 6.
Pour les cartes avec des cercles proportionnels, la légende est constituée de quatre cercles qui suivent les ordres de grandeur de l’ensemble des stocks propres à la région (toutes modalités et heures confondues). Cette légende conserve néanmoins l’information relative aux valeurs propres à la modalité sélectionnée grâce au report automatique et en toutes lettres (dans la couleur de la modalité) des valeurs maximum, minimum et moyenne de la modalité pour chacune des heures de la journée.
1.4.3 L’animation temporelle
La timeline, située au dessus de la carte, permet un affichage de la répartition spatiale des modalités heure par heure. Par défaut, elle est fixé à 14 heures. Elle peut être manipulée de façon animée, en cliquant sur le bouton « Play », ou de façon interactive grâce au curseur. En mode animation, le curseur bouge selon un pas de temps d’une seconde. Arrivé au bout de l’axe, à 3 heure du matin, il revient automatiquement à 4 heure. L’animation s’arrête automatiquement après un défilement de 24 heures. En mode interactif, le curseur peut être manipulé en cliquant sur l’axe ou en le faisant glisser le long de l’axe. Sur les graphiques, une ligne grisée se déplace au même rythme que la timeline.
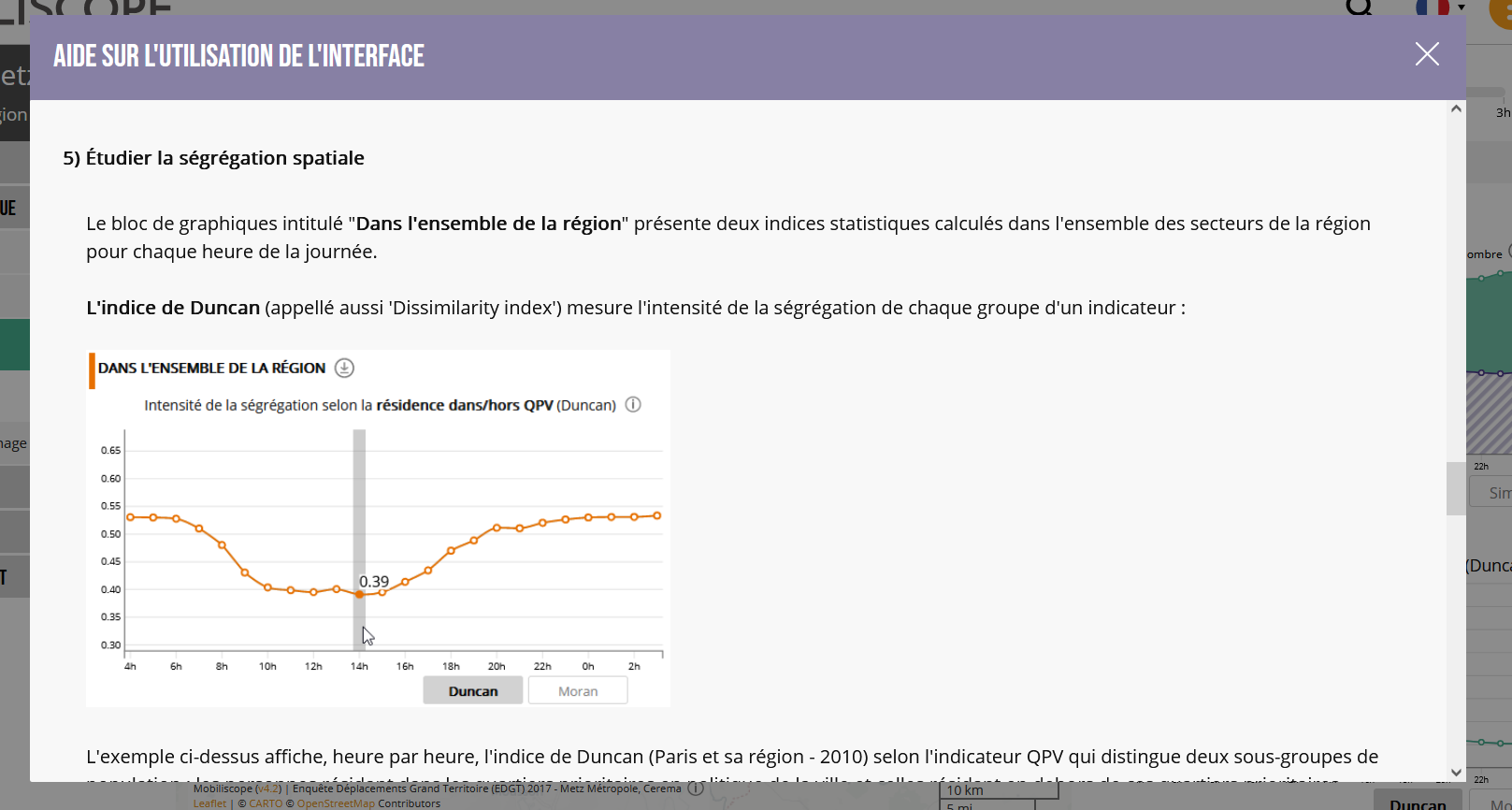
1.4.4 Les graphiques
En haut, un premier bloc de graphiques permet d’afficher les valeurs prises sur 24h par la modalité choisie dans un secteur donné (cliqué). Un premier graphique, dans l’onglet « Simple » permet d’afficher la courbe de la modalité seule ; un second onglet « Empilé » permet de comparer les valeurs prises par la modalité en comparaison avec les valeurs prises par les autres modalités du même indicateur sous forme d’un graphique en aires empilées (stacked area chart) : plus la zone colorée est large, plus la valeur prise par la modalité est élevée par rapport aux autres. La zone correspondant à la modalité affichée dans la carte est en couleur pleine tandis que les zones correspondant aux autres modalités sont hachurées. La signification des couleurs affichées dans le graphique « Empilé » est lue dans le menu des indicateurs qui fait office de légende. Au survol des graphiques, une infobulle permet de connaître les valeurs exactes des informations affichées, heure par heure.
En bas, un second bloc de graphiques permet l’affichage des valeurs prises par deux indices de distribution spatiale : l’indice de Duncan (indice de ségrégation) et l’indice de Moran (indice d’autocorrélation spatiale). Ces indicateurs sont calculés pour l’ensemble de la région aux 24h de la journée et permettent d’évaluer l’évolution du niveau de ségrégation au cours de la journée pour tel ou tel groupe social. Les onglets « Duncan » et « Moran » permettent de passer d’un graphique à l’autre. Dans les graphiques de Duncan et de Moran, les valeurs minimum et maximum sont les mêmes pour toutes les modalités d’un même indicateur afin de permettre la comparaison. De plus, l’amplitude entre le minimum et le maximum ne peut pas être en deçà de 0,4 pour ne pas donner trop d’importance à d’éventuelles variations mineures dans la structure spatiale. Toujours dans un souci de comparabilité, la courbe de toutes les modalités s’affiche sur le graphique : la modalité observée est en couleur pleine, les cercles figurant les indices pour chaque heure s’affichent, ainsi que les indices au survol de la souris ; les autres modalités de l’indicateur s’affichent en transparence.
Pour tous les graphiques, l’axe des abscisses correspond aux 24 heures de la journée et commence à 4 heures du matin, comme la timeline. L’axe des ordonnées est quant à lui affiché avec 2 décimales pour les indices de Duncan et de Moran, sans décimale pour les modalités calculées en parts, et en milliers (abrégé « k ») pour les modalités calculées en stocks.
1.4.5 Autres fonctionalités
Le téléchargement des données
Les données de présence horaire (et les indices de ségrégation) affichées dans la géovisualisation sont proposées au téléchargement par simple clic. Elles sont fournies au format .csv et accompagnées d’un dictionnaire (readme.md stocké dans [www/data-settings], d’un fichier géographique (format .geojson) et d’un fichier résumant les termes de la licence ODbL.
![]() au dessus de la carte centrale : valeurs agrégées par secteur selon l’indicateur et le mode de représentation sélectionné
au dessus de la carte centrale : valeurs agrégées par secteur selon l’indicateur et le mode de représentation sélectionné
![]() à côté du graphique du bas : valeurs des indices de ségrégation pour l’ensemble de la région selon l’indicateur sélectionné et l’indice de ségrégation choisi.
à côté du graphique du bas : valeurs des indices de ségrégation pour l’ensemble de la région selon l’indicateur sélectionné et l’indice de ségrégation choisi.
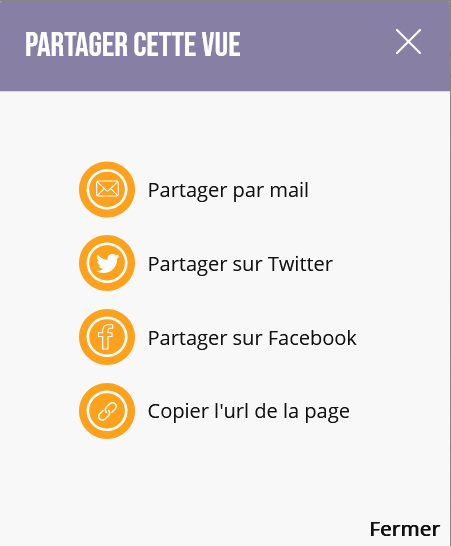
Le partage de vue
Depuis la version 4.1, certaines sélections effectuées dans la géovisualisation - choix d’une modalité et de son mode représentation dans le menu des indicateurs, choix du secteur et choix de l’heure - sont stockées dans l’URL de la page. Cette fonctionnalité facilite le partage d’une vue particulière.
Ce partage peut se faire par copier/coller de l’URL dans la barre de recherche du navigateur ou via le bouton ![]() situé à droite de la timeline. Quatre modes de partages sont proposés
situé à droite de la timeline. Quatre modes de partages sont proposés
Les pop-ups et le help
Au clic sur les boutons ![]() un pop-up apparaît apportant des informations, selon le contexte, sur les indicateurs et leurs modalités, sur les estimations de la population représentée et le découpage en secteurs, sur les indices de ségrégation ou encore sur la source des données.
un pop-up apparaît apportant des informations, selon le contexte, sur les indicateurs et leurs modalités, sur les estimations de la population représentée et le découpage en secteurs, sur les indices de ségrégation ou encore sur la source des données.
Le bouton ![]() situé à droite de la timeline renvoie au help, une aide rédigée et illustrée sur l’utilisation de l’interface
situé à droite de la timeline renvoie au help, une aide rédigée et illustrée sur l’utilisation de l’interface
2 Les services
2.1 Dépôts GitLab
Le projet Mobiliscope utilise deux dépôts git (librement accessibles) :
https://gitlab.huma-num.fr/mobiliscope/data-process
Dans ce git, on trouvera l’ensemble des scripts de pré-traitement des données liées au Mobiliscope.https://gitlab.huma-num.fr/mobiliscope/www
Il s’agit du code source des pages web du Mobiliscope. C’est à partir de ce git qu’est déployé le Mobiliscope. Ce git dispose de plusieurs branches.La branche “master” correspond à la version stable du Mobiliscope, celle qui est en production et qui porte les tags des versions mises en production.
Les autres branches sont utilisées pour le développement.
Remarque : De sa première version jusqu’à sa version 4.2, le Mobiliscope fonctionnait sans système de base de données. Les données lues par l’application étaient alors stockées « en dur » à côté du code source sur le git. Certaines données n’étant pas ouvertes, l’outil était développé sur un git privé. Puis, à la suite de chaque mise en ligne, le code source ainsi que les scripts de pré-traitement de la donnée étaient copiés (sans les données donc) sur un git public : https://github.com/Geographie-cites/mobiliscope.
2.2 Outil WampServer
WampServer est l’outil de développement web utilisé par les membres de l’équipe sous Windows. Il permet d’installer localement sur sa machine un environnement php/apache, reproduisant localement les configurations d’un serveur d’hébergement. Via WampServer, il est possible d’afficher dans son navigateur les pages du Mobiliscope et de visualiser immédiatement les modifications du code.
Installation de wampserver
L’installation de WampServer est bien expliquée ici : https://wampserver.aviatechno.net/
La version 3.3.0 est utilisée par l’équipe
La version 3.3.5 - mai 2024 - (Wampserver 3.3.5 64 bit x64 - Apache 2.4.59 - PHP 8.3.6 - MySQL 8.3.0 - MariaDB 11.3.2) fonctionne aussi.
Création d’un virtual host wampserver
Prérequis : avoir git-cloner le dossier www du code source du Mobiliscope
- Lancer wampserver, puis dans la barre menu / îcones cachées
- clic gauche îcone wamp (verte si service allumé) > vos virtualHosts > Gestion virtualHost
- La page add_vhost.php s’ouvre dans votre navigateur
- renseigner un nom de virtualHost ex : mobiliscope-dev
- renseigner le chemin d’accès au dossier www contenant le code source
- démarrer la création du virtualHost
- relancer le DNS
- clic droit sur l’îcone wamp > outils > redémarrage DNS
Attention : couper son antivirus et son pare-feu le temps de la création du virtualHost
- Ouverture du Mobiliscope local dans un navigateur
- clic gauche îcone wamp (verte si service allumé) > vos virtualHosts > mobiliscope-dev
- ou mobiliscope-dev dans navigateur
Pour un affichage optimal, avec le css et l’interactivité, il reste à installer les dépendances (à condition que la librairie node.js soit bien installée sur la machine locale)
2.3 Compilation avec Webpack
Webpack est un module bundler qui permet de compiler les fichiers css et javascript du code source et d’ainsi optimiser leur bon fonctionnement par n’importe quel navigateur.
Installation de webpack
Créer le paquets node.js dans le dossier www du code source
cd C:/.../wwwnpm installCela crée le dossier [node_modules] et mettra à jour le fichier package-lock.json. (Si on rencontre un problème dans l’installation, une solution peut-être de supprimer “à la main” nodes-module et package-lock.json et de relancer npm install)
Utilisation de webpack
Prérequis : Avoir créer son local host wamp (cf. Section 2.2) ; avoir cloner le git dédié et être sur la branche git souhaitée (cf. Section 2.1)
Se brancher sur le répertoire contenant le code source avec la commande :
cd C:/.../wwwLancer npm en mode
développement :
npm run build:dev(npm s’exécute en fond tant que le service n’est pas stoppé. Pour l’arrêter, crtl + c puis o)ou en mode production :
npm run build:prod(npm s’exécute une seule fois)
2.4 Hébergement sur la VM HumaNum
Le Mobiliscope est hébergé sur une machine virtuelle (VM) d’Huma-Num. (cf. adresse IP de la VM #PrivateAccess)
Remarque : la connexion à la VM d’HumaNum (par ssh) n’est pas possible en dehors de la France
2.4.1 Connexion par clef ssh
Dans la console de commande :
ssh mobiliscope@mobiliscope.huma-num.frou
ssh -m hmac-sha2-512 mobiliscope@mobiliscope.huma-num.fr
Remarque : Si l’ordinateur n’est pas configuré pour utiliser le bon algo de cryptage (le ssh crypte les données) et que l’on reçoit le message erreur : “Corrupted MAC on input” ; ”message authentication code incorrect”, la solution est d’ajouter -m hmac-sha2-512 à la commande ssh. Cf. ici
Pour ajouter, remplacer ou supprimer une clef ssh :
cd .sshnano authorized_keys
Remarque : Pour trouver la ssh publique de son ordi, ouvrir le fichier id_rsa.pub stocké dans C/Users/Nom/.ssh
2.4.2 Une prod et une pre-prod
prod : mobiliscope.cnrs.fr
pre-prod : test.mobiliscope.cnrs.fr (accessible par login& mot de passe. (cf. #PrivateAccess)
Création login & mot de passe :
Le login et mot de passe (crypté) sont dans un fichier .htpasswd situédans
/var/www/.Pour créer (ou remplacer) le .htpasswd :
aller dans
cd /var/www/exécuter la commande
sudo htpasswd -c /var/www/.htpasswd loginen remplaçant “login” par le login que l’on souhaiteindiquer dans la console le mot de passe souhaité
le login/mot de passe (avec le password sous forme cryptée
login:) est alors automatiquement stocké dans le .htpasswd
Activer login/mot de passe
Actuellement il y a besoin d’un login/mot de passe pour accéder à la version en pre-prod (mais pas besoin de mot de passe pour la version en prod). L’activation du login/password pour la preprod se fait dans le .htaccess (situé dans /var/www/test.mobiliscope.cnrs.fr), en ajoutant ces 4 lignes au tout début du .htaccess
AuthType Basic
AuthName "Mobiliscope Test"
AuthUserFile /var/www/.htpasswd
Require valid-user
2.4.3 Déploiement en prod et pre-prod
Etape 1
Avant chaque déploiement, lancer webpack (en mode prod) sur la branche du git www
cd D:\Documents\Mobiliscope\GitlabHumaNum\wwwnpm run build:prod
Et pusher le dist sur la branche du git www
Etape 2
D’abord, se connecter à la VM HumaNum en ssh (cf. ci-dessus).
Puis
pour déployer sur la pre-prod, aller dans :
cd /var/www/test.mobiliscope.cnrs.fr/Ou pour déployer sur la prod, aller dans :
cd /var/www/mobiliscope.cnrs.fr/
Etape 3
Faire un pull en sudo en indiquant le nom de la branche git du dépot www :
sudo git pull origin {branche}(par exemplesudo git pull origin masterpour un pull de la branche master)Pour déployer à partir d’un commit particulier d’une branche :
sudo git checkout {ID_DU_COMMIT}Pour avoir la liste des commits disponibles avec leur id :
sudo git log
Etape 4 (en cas de déploiement sur la prod)
Sur GitLab, merger la branche déployée sur master si ce n’est pas déjà le cas
Mettre un tag sur le commit correspondant à la version mise en prod afin de retrouver simplement les anciens états du code correspondant à chaque mise en prod. Les tags sont formalisés avec la version du Mobiliscope et la date de publication (par exemple, v4_2_online_2023/06/15)
2.4.4 Configuration apache
Fichier de configuration
sudo vi /etc/apache2/apache2.conf
Répertoires des sites :
prod : /var/www/mobiliscope.cnrs.fr
pre-prod: /var/www/test.mobiliscope.cnrs.fr
Hôtes virtuels
sudo vi /etc/apache2/sites-available/vhosts.conf
Logs du serveur
tail -f /var/log/apache2/mobiliscope_error.logtail -f /var/log/apache2/mobiliscope_access.logtail -f /var/log/apache2/test-mobiliscope_error.logtail -f /var/log/apache2/test-mobiliscope_access.log
Actions apache
sudo systemctl restart apache2sudo systemctl stop apache2sudo systemctl start apache2
2.5 Stockage des données via Minio
2.5.1 Minio HumaNum
Depuis la version 4.3, le Mobiliscope utilise MinIO comme base de données. Ce service, mis en place et maintenu par l’équipe, est hébergé sur les serveurs d’Huma-Num « aux côtés » des autres services de l’écosystème du Mobiliscope. En séparant physiquement les données du code source, il permet d’alléger le git et de sécuriser les données.
Deux MinIO ont été installés sur la machine HumaNum:
- l’un pour la version de production (i.e. les données lues par le Mobiliscope de prod)
- l’autre pour la version de pre-prod et pour le dev.
La production des données intégrées aux MinIO ainsi que leur architecture et système de versionnement sont décrits dans les Section 4 et Section 5 du guide.
Accès par tunnel ssh
Les données stockées dans ces deux MinIO sont en accès restreint (avec login et mots depasse. cf #PrivateAccess). Ils sont accessibles en se connectant au serveur HumanNum via un tunnel ssh entre la machine locale et le serveur HumaNum pour faire croire au serveur d’HumaNum qu’on est sur son réseau interne. C’est le même principe qu’un vpn.
Remarque : la connexion au Minio hébergés sur HumaNum (par ssh) n’est pas possible en dehors de la France
Accès au Minio de prod
- Mapper port 9001 pour l’interface minio de prod (port 9000 pour l’api minio de prod)
ssh -m hmac-sha2-512 -L 9001:localhost:9001 mobiliscope@mobiliscope.huma-num.fr
- Ensuite aller sur http://localhost:9001 pour accéder au minio de prod et uploader données etc. comme si on était dans le serveur
Accès au Minio de test
- Mapper port 9011 pour l’interface minio de test (port 9010 pour l’api minio de test)
ssh -m hmac-sha2-512 -L 9011:localhost:9011 mobiliscope@mobiliscope.huma-num.fr
- Ensuite aller sur http://localhost:9011 pour accéder au minio de test et uploader données etc. comme si on était dans le serveur
Remarque : Pour casser le tunnel (qui ralentit le serveur) il faut taper CTRL + C sur windows.
Configuration de la version des données utilisées (settings.json)
Pour choisir quelle version des données est utilisée par le Mobiliscope de prod (et de pre-prod); il faut modifier les ‘majorVersion’ et ‘minorVersion’ du fichier settings.json stocké dans /var/www
cd /var/www/nano settings.json
Le fichier settings.json contient pour chaque environnement :
une clé: le nom de l’environnement (production ou test)
une valeur de paramétrage pour:
minioEndPoint: l’url du serveur minio sélectionnéminioAccessKey: le login du minio sélectionné #PrivateAccess,minioSecretKey: le password du minio sélectionné #PrivateAccess,majorVersion: la version majeure du minio sélectionnéminorVersion: la version mineure du minio sélectionné
2.5.2 Minio local
Pour les phases de développement, il est aussi possible d’utiliser un MinIO installé localement sur son ordinateur.
Pré-requis : avoir git-cloner le code source du Mobiliscope et être sur une branche fonctionnant avec MinIO
Install du minio local (windows)
Créer dans le disque C un dossier qui accueillera la base de données. Exemple : C:/…/database
Sur la page officielle du service, télécharger le MINIO SERVER : https://min.io/download#/windows
Déplacer le fichier minio.exe dans le dossier créé : C:/minio_data/minio.exe
Ouvrir une invite de commande et exécuter les commandes suivantes (sans spécifier au préalable le répertoire avec cd)
setx MINIO_ROOT_USER admin
setx MINIO_ROOT_PASSWORD password
C:\\minio_data\\minio.exe server C:\\minio_data\\mobiliscope --console-address ":9001"
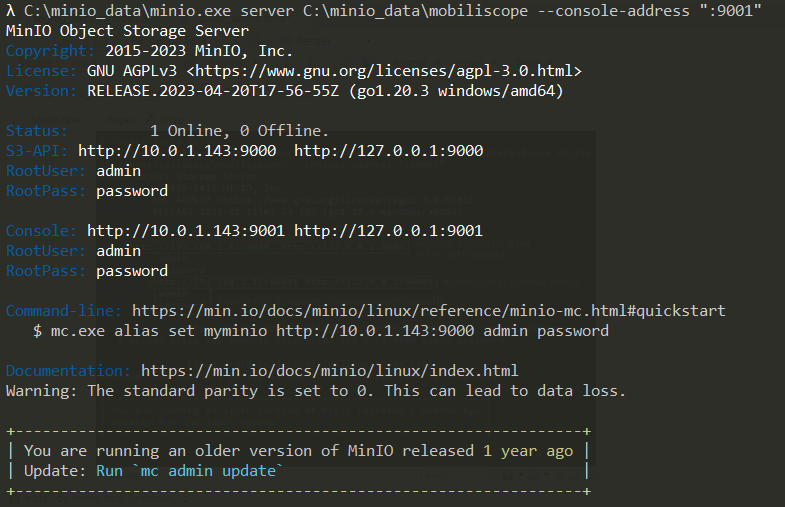
À noter : 1) privilégier les chemins absolus plutôt que relatifs ; 2) mettre les chemins entre guillemets (double quote) s’ils comportent des espaces ou des accents ; 3) il est possible qu’en local, l’ordinateur ne puisse pas ouvrir le service MinIO sur le port 60001, il faut alors changer la console-address jusqu’à trouver un port libre (par exemple 9001). Attention il faut répercuter les changements de port dans la configuration du fichier local settings.json (cf. Section 2.6) il est préférable d’utiliser l’adresse interne 127.0.0.1 au lieu de son équivalant 192.168.1.13.
Ouvrir l’interface MinIO. Dans un navigateur, copier l’URL de la console, soit, dans notre cas http://127.0.0.1:9000 (renseigner ensuite son login et mot de passe, soit, dans notre cas, admin et password)
Par la suite, chaque fois qu’on veut utiliser les données stockées dans le MinIO local, il faut lancer l’exécutable avec la commande
C:\\minio_data\\minio.exe server C:\\minio_data\\mobiliscope --console-address ":9001"Pour arrêter l’exécution de MinIO, il faut taper CTRL + C dans le terminal minio.exe
Organiser les données dans les buckets.
Un bucket est similaire à un dossier dans un système de fichiers. Pour le développement en local, il est préférable d’avoir une structure de buckets identique au Minio Huma-Num
Pour ajouter des répertoires et fichiers au MinIO, il faut absolument passer par sa console et ne pas ajouter directement les fichiers dans le répertoire C:/…/database (cela casse tout).
Pour créer un bucket, il suffit de cliquer sur le bouton « Create Bucket », puis d’indiquer son nom.
Pour modifier manuellement un bucket - onglet « Object Browser » - cliquer sur le nom du bucket à modifier - cliquer sur le bouton « Upload » ou verser ses dossiers par drag and drop (certaines fonctionnalités comme le drag and drop ne marchent pas lorsqu’on est sur la console MinIO via Firefox, préférer Chrome)
Install du minio local (mac)
https://min.io/download#/macos
brew upgrade
brew install minio/stable/minio
mkdir ~/Data/mobiliscope
sudo MINIO_ROOT_USER=minioadmin MINIO_ROOT_PASSWORD=minioadmin minio server ~/Data/mobiliscope --console-address '127.0.0.1:60001' --address '127.0.0.1:60000'
Se loguer sur la console minio : http://127.0.01:60001/login (avec minioadmin / minioadmin)
Créer un bucket nommé mobiliscope et lui donner l’accès public
2.6 Installation du Mobiliscope sur son ordi en local
2.6.1 Pré-requis
Cloner sur son ordinateur le code source du logiciel Mobiliscope depuis le dépôt GitLab (https://gitlab.huma-num.fr/mobiliscope/www) & avoir vérifié qu’on est bien sur la bonne branche
Démarrer Wampserver pour pouvoir ouvrir le Mobiliscope local (http://mobiliscope-dev) dans son navigateur (cf. Section 2.2)
Créer sur son ordinateur deux fichiers de config au même niveau que le répertoire [www] cloné :
un fichier .env qui permet de spécifier « à la main » l’environnement choisi (local ou test ou production)
soit
environment=localsoit
environment=testsoit
environment=production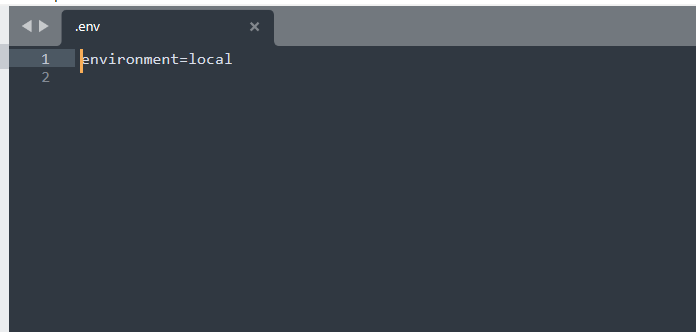
un fichier settings.json qui contient le jeu de paramètres de connexion (URL et logins/password #PrivateAccess) des Minio pour les 3 environnements (local, test et production)
une clé: le nom de l’environnement (local, test, production)
une valeur de paramétrage pour:
`minioEndPoint`: l’url du serveur minio à utiliser
`minioAccessKey`: le login du minio sélectionné #PrivateAccess,
`minioSecretKey`: le password du minio sélectionné #PrivateAccess,
`majorVersion` : la version majeure du mobiliscope à utiliser
`minorVersion`: la version mineure du mobiliscope à utiliser
Code 1: Connexion MinIO settings.json
{ "local": { "minioEndPoint": "http://127.0.0.1:9000", "minioAccessKey": "admin", "minioSecretKey": "password", "majorVersion": "zenodo", "minorVersion": "20230706opendata" }, "test": { "minioEndPoint": "http://minio.mobiliscope.cnrs.fr:9110", "minioAccessKey": "#PrivateAccess", "minioSecretKey": "#PrivateAccess", "majorVersion": "vtest", "minorVersion": "20230706" }, "production":{ "minioEndPoint": "http://minio.mobiliscope.cnrs.fr:9100", "minioAccessKey": "#PrivateAccess", "minioSecretKey": "#PrivateAccess", "majorVersion": "v4-3", "minorVersion": "20230706" } }
Remarque : Le fichier settings.json contient des infos en #PrivateAccess. Il ne doit donc pas être commité. C’est pour cela qu’il est « en dehors » du dépôt git [www] et qu’il doit être créé manuellement (comme aussi le fichier .env qui va avec..)
Lancer Webpack seulement si on veut faire des changements dans les fichiers du dossier src du dépôt www
D’abord, installer Webpack (cf. Section 2.3). Cela créera le dossier [node_modules] et mettra à jour le fichier package-lock.json.
Puis, lancer Webpack en mode développement :
npm run build:dev(ou bien en mode production :npm run build:prod=> npm s’exécute une seule fois)
2.6.2 Connexion aux données minio
L’utilisateur peut ensuite choisir d’afficher sur son ordi les données qu’il aura stockées sur son minio local ou bien celles qui sont stockées sur les minios d’HumaNum en #PrivateAccess.
Pour le minio local
Pré-requis : Avoir créé un minio local (cf. Section 2.5.2)
Ensuite, à chaque fois que l’on veut accéder au minio local, il faut lancer l’exécutable avec la commande
C:\\minio_data\\minio.exe server C:\\minio_data\\mobiliscope --console-address ":9001"
Dans le settings.json, pour l’environnement local, vérifier la configuration du “minioEndPoint” (“minioEndPoint”: “http://127.0.0.1:9000”) et vérifier aussi les autres paramètres (“minioAccessKey”, “minioSecretKey”, “majorVersion”, “minorVersion”).
Pour ouvrir ensuite l’interface MinIO, copier l’URL de la console, soit, dans notre cas http://127.0.0.1:9000 (renseigner ensuite son login et mot de passe, soit, dans notre cas, admin et password)
Remarque: Il est possible d’uploader dans son minio local les données en open-data issues du dépôt Zenodo. Ce dossier, une fois dezippé, contient toutes les données nécessaires pour faire fonctionner le Mobiliscope (sauf le dossier [flowData] pour des questions de confidentialité). cf. Section 5.4
Pour les minios HumaNum
Cette connexion aux minios HumaNum n’est possible qu’avec les #PrivateAccess
Remarque : La connexion au minios d’HumaNum depuis sa machine nécessite un certain nombre de manipulations (mais certaines ne sont à faire qu’une fois !).
Etape 1. Régler le problème de certificats SSL (windows)
Sous windows, les échanges entre minio d’HumaNum et la machine locale sont sécurisés, ce qui bloque l’accès au minio. Ce qu’il faut faire:
A partir de https://curl.haxx.se/docs/caextract.html, télécharger cacert.pem et le mettre dans C:/wamp64
Dans C:/wamp64/, ouvrir le php.ini de apache (dans C:\wamp64\bin\apache\apache2.4.54.2\bin) ET le php.ini de php (dans C:\wamp64\bin\php\php7.4.33)
Dans chacun de ces deux php.ini, à la suite des lignes
[curl]; A default value for the CURLOPT_CAINFO option. This is required to be an; absolute path.;curl.cainfo =ajouter
curl.cainfo="C:/wamp64/cacert.pem"openssl.cafile="C:/wamp64/cacert.pem"Figure 11: mofication des fichiers php.ini 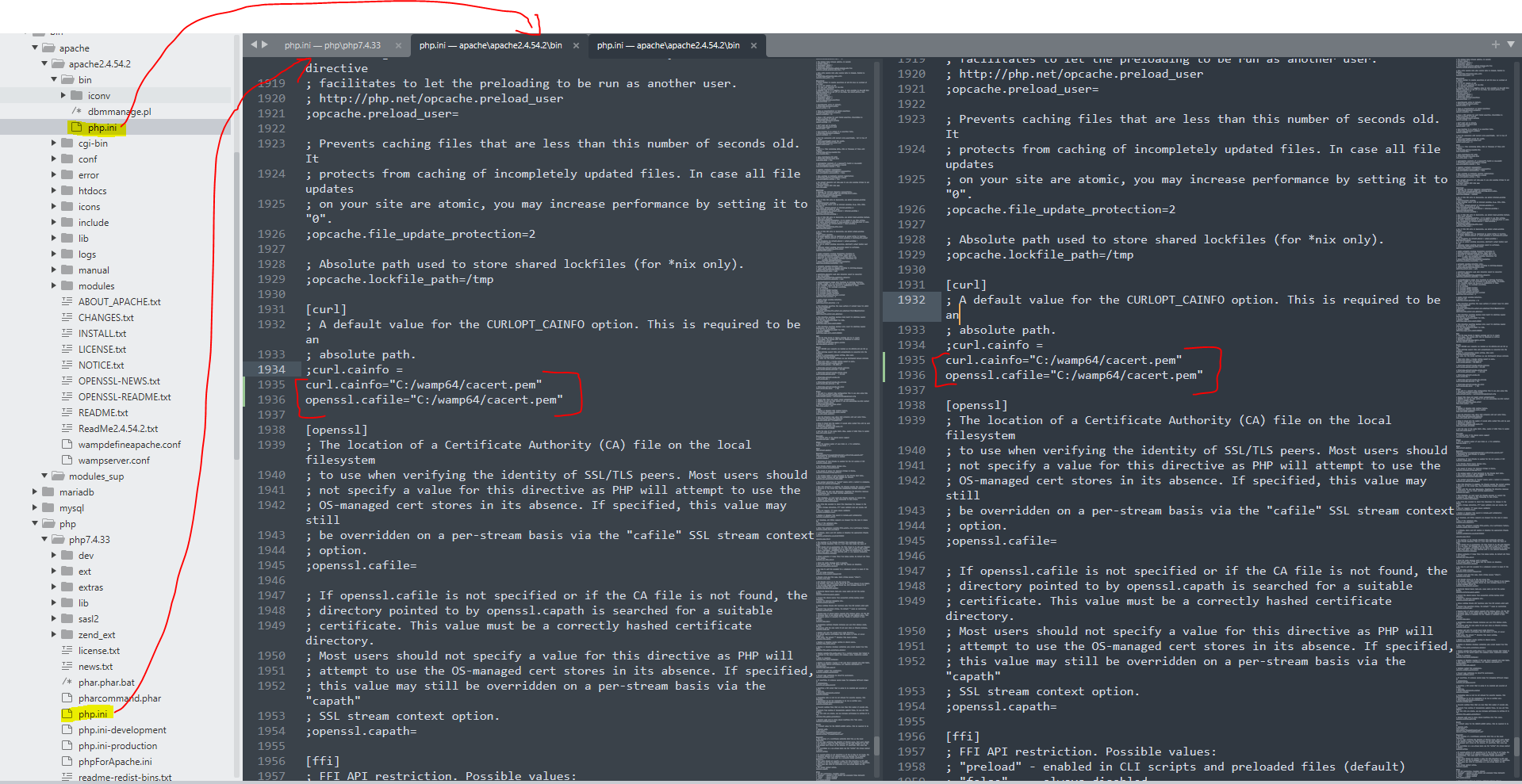
Redémarrer Wamp
=> Cette manipulation n’est à faire qu’une fois :)
Etape 2. Mapper la machine par tunnel ssh
Les ports sont fermés sur le serveur Humanum et l’api Minio ne répond qu’en https. Donc nous avons ajouté un certificat SSL sur http://minio.mobiliscope.cnrs.fr. L’astuce consiste à mapper la machine locale vers un service https interne au serveur Humanum et taper sur l’api
- Déclarer sur votre machine locale un host (qui fonctionnera pour se connecter au minio de prod ou de test)
Ouvrir le fichier hosts (C:\Windows\System32\Drivers\etc\hosts) et ajouter à la fin du fichier :
127.0.0.1 minio.mobiliscope.cnrs.fr
Ainsi toutes les requêtes en minio.mobiliscope.cnrs.fr:XXX passent par votre machine (un ping minio.mobiliscope.cnrs.fr devrait donner votre ip locale)
=> Cette manipulation n’est à faire qu’une fois :)
Remarque : Si on rencontre une erreur d’autorisation pour ouvrir et enregistrer le fichier hosts (un fichier système de Windows), cela vient du fait que l’on n’a pas ouvert le bloc-notes en administrateur. Pour le faire : (1) Dans la zone de recherche de Windows, saisir bloc-notes ; (2) Faire un clic droit sur le bloc-notes en résultat de la recherche ; (3) Dans le menu déroulant, cliquez sur Exécuter en tant qu’administrateur. cf. (https://kinsta.com/fr/base-de-connaissances/fichier-hosts-windows-10/)
Etape 3. Faire un tunnel ssh vers les minios HumaNum
A chaque fois que l’on veut accéder au minio de prod, il faut mapper le port local 9100
ssh -m hmac-sha2-512 -L 9100:minio.mobiliscope.cnrs.fr:9000 mobiliscope@mobiliscope.huma-num.frDans le settings.json, pour l’environnement production, vérifier la configuration du “minioEndPoint” (“minioEndPoint”: “http://minio.mobiliscope.cnrs.fr:9100”)
A chaque fois que l’on veut accéder au minio de test, il faut mapper le port local 9110
ssh -m hmac-sha2-512 -L 9110:minio.mobiliscope.cnrs.fr:9010 mobiliscope@mobiliscope.huma-num.frDans le settings.json, pour l’environnement test, vérifier la configuration du “minioEndPoint” (“minioEndPoint”: “http://minio.mobiliscope.cnrs.fr:9110”)
Remarque : Pour casser le tunnel (qui ralentit le serveur) il faut taper CTRL + C sur windows.
2.7 Autres services de suivi
2.7.1 UpTimeRobot - outil de monitoring de site web
L’outil UptimeRobot propose un monitoring qui alerte directement si le site web que l’on gère tombe en panne et devient momentanément indisponible. La plateforme est en mesure de notifier (par email notamment) de toute panne sur le site web, le serveur ou encore les certificats SSL.
UptimeRobot propose une version gratuite avec la possibilité de monitorer jusqu’à 50 URL avec un intervalle de 5 minutes. Elle permet aussi de renseigner le temps de réponse et sa moyenne sur les dernieres 24 heures.
Les sites de prod et de pre-prod sont monitorés via https://uptimerobot.com/ (#PrivateAccess)
Remarque : C’est en monitorant le Mobiliscope hébergé sur le serveur du CNRS jusqu’à la v4.2 que l’équipe du Mobiliscope a pu connaitre la fréquence des indisponibilités et les temps élevés de réponse. C’est un des raisons pour lesquelles l’équipe a choisi de migrer le service sur le serveur HumaNum.
2.7.2 Matomo - service d’analyse d’audience
Huma-Num met à disposition du projet Mobiliscope une instance Matomo qui est hébergée sur les infrastructures d’Huma-Numqui et qui permet d’analyser le trafic et la fréquentation du site http://mobilicope.cnrs.fr/ . Cette alternative à Google Analytics par exemple, permet de suivre l’usage d’un site web tout en conservant les données utilisateurs au sein du cloud Huma-Num.
Les statistiques de fréquantation sont anonymisées dans le respect du règlement européen de protection des données et du cadre recommandé par la CNIL. Matomo est parametré de façon à protéger au maximum les données dans le respect du RGPD. IAucun cookie tiers n’est déposé sur le navigateur des utilisateurs du site. Il n’y a donc pas besoin de mettre un bandeau cookie pour recueillir le consentement des utilisateurs avant de déclencher Matomo.
L’accès au service Matomo hébergé par Huma-Num se fait sur https://analyseweb.huma-num.fr/ via l’ID d’Huma-Num (#PrivateAccess)
Dans les pages index.php, geoviz.php et info.php (cf. dossiers par langue [french], [english], [espanol]), un code javascript est ajouté (immédiatement avant la balise de fermeture </head>).
<!-- Matomo -->
<script>
var _paq = window._paq = window._paq || [];
/* tracker methods like "setCustomDimension" should be called before "trackPageView" */
_paq.push(['trackPageView']);
_paq.push(['enableLinkTracking']);
(function() {
var u="https://analyseweb.huma-num.fr/";
_paq.push(['setTrackerUrl', u+'matomo.php']);
_paq.push(['setSiteId', '325']);
var d=document, g=d.createElement('script'), s=d.getElementsByTagName('script')[0];
g.async=true; g.src=u+'matomo.js'; s.parentNode.insertBefore(g,s);
})();
</script>
<!-- End Matomo Code -->3 Le Mobiliscope - Code logiciel
Le dépôt git dédié : https://gitlab.huma-num.fr/mobiliscope/www
3.1 Organisation du code
3.1.1 Architecture générale
À la racine du dossier, on trouve un certain nombre de fichiers et de dossiers qui sont soit liés au fonctionnement/configuration web en général soit liés plus spécifiquement au projet Mobiliscope :
Spécification web
informations générales concernant le projet web :
readme.md
sitemap.xml
HTTP Apache : spécification à destination du serveur d’hébergement
- .htaccess
composer : gestion des dépendances PHP, déclaration des librairies utiles au projet
composer.json
composer.phar
webpack : configuration de webpack ; fichiers générés automatiquement par npm
webpack.config.js
package.json
package-lock.json
postcss.config.js
dist
node_modules (gitignore)
.nvmrc
combine.php
dossier « vendor » : stockage de ressources externes
Autres fichiers :
favicon.ico : icone Mobiliscope pour les barres de recherche des navigateurs
.gitignore : fichier de configuration git pour empêcher le traçage de certains fichiers
Spécification Mobiliscope
Connexion au MinIO :
- minio-settings.php : fonction d’appel des données stockées dans le minIO.
- minio-ajax-loader.php : chargement asynchrone des données minIO
- minio-debug.php : outil utilisé lors du développement pour debugger l’accès au minio
geoviz_menu.php : génération dynamique du menu des indicateurs des pages de géovisualisation (contenu textuel et balisage html), s’adapte à chaque ville et prend en entrée le fichier menu.json des données par ville (cf. Section 5.1.1). Important à savoir, le script crée, pour chaque bouton du menu, l’attribut « data-iduphp » qui stocke la clé unique de la donnée (en puisant l’information dans menu.json).
zip-streamer.php : génération dynamique d’un dossier zippé pour le téléchargement des données de présences observées pour une ville donnée et un indicateur donné.
Les dossiers suivants concernent également spécifiquement le Mobiliscope
data-settings : dossier contenant les données globales décrites dans la Section 5.1.2.
pdf : ressources pdf (articles scientifiques ou grand public) partagés dans les pages info du site
src : contient le code source (scripts javascript et styles css mais également fonts et images) qui est compilé par webpack dans le dossier « dist ». Le contenu de ce dossier est détaillé plus bas.
« french », « english », « espanol » : contient les scripts spécifiques aux trois langues
3.1.2 Une organisation par langue
Le Mobiliscope étant trilingue, on trouvera trois dossiers langues (« english », « espanol », « french »). À l’intérieur de ces dossiers (cf. Figure 13), la structure est strictement identique (les différences concernent les spécificités de langue), elle correspond à l’architecture des pages html du site (cf. Section 1.3).
Le fichier settings.php est un fichier de configuration qui définit et initialise les chemins internes des différentes pages pour une langue. Ce fichier est appelé par toutes les pages du site.
La page d’accueil
À la racine des dossiers langue, on trouvera le traditionnel fichier index.php qui correspond à la page par défaut lorsqu’on arrive sur le site. Il s’agit de la page d’accueil. L’index est factorisé : l’entête (topbar.php) et le pied de page (footer.php) sont écrits dans des fichiers à part, ainsi que les témoignages d’utilisatrices du Mobiliscope (bloc-témoignages.php). De même, les cartes affichées sur la page d’accueil sont codées dans un script javascript (map-printer.js) situé dans le dossier « src ». Les librairies utilisées pour cette page sont appelées à la fin du fichier.
Les pages informations
La structure des pages d’informations est toujours la même (cf. Figure 14), seul le contenu change. C’est pourquoi on trouvera dans le sous-dossier « info » un fichier unique, info.php qui structure ces pages. L’info.php est factorisé : le menu des pages d’information est dans un fichier à part (left-menu.php) ainsi que le contenu textuel. On trouvera donc dans le sous-dossier « subpages », autant de fichiers qu’il existe de pages.
Certaines pages d’information contiennent des tableaux. Dans ce cas les fichiers correspondant ont également étaient factorisés : on trouvera ces tableaux dans le sous-dossier « table ». L’affichage dynamique de ces tableaux est assuré par la librairie dataTables et autres dépendances. L’appel de ces librairies se fait à la fin du fichier info.php.
Lorsque l’on souhaite ajouter une nouvelle page d’information, il faut :
- écrire le contenu avec un balisage html dans un nouveau fichier du dossier « subpages »
- penser à déclarer cette nouvelle page dans la variable $subpages du fichier settings.php.
- modifier en conséquence le fichier left-menu.php
Si on modifie le chemin d’un page d’information (par exemple si on passe de https://mobiliscope.cnrs.fr/fr/info/open/evolution à https://mobiliscope.cnrs.fr/fr/info/methods/evolution), il faut penser à l’indiquer dans le .htaccess
RewriteRule ^fr\/info\/open\/evolution$ /fr/info/methods/evolution [L,R=301]
RewriteRule ^en\/info\/open\/evolution$ /en/info/methods/evolution [L,R=301]
RewriteRule ^es\/info\/open\/evolution$ /es/info/methods/evolution [L,R=301]Les pages de géovisualisation
Quelque soit la ville à explorer, la structure des pages de géovisualisation est identique. Celle-ci est défini dans le fichier geoviz.php (l’unique fichier du sous-dossier « geoviz »). Les fonctionnalités des pages de géovisualisation sont assurées par des scripts situés soit à la racine du projet, soit dans le dossier « src ».
Les éléments de la page - menu, cartes, graphiques, timeline - ont été codés en javascript, principalement avec la librairie d3.js. Le script load.js (dans src/scripts) constitue le cœur de ce travail.
3.1.3 Le code source de la géovisualisation
On trouvera dans le dossier « src » les librairies et scripts javascript (« src/scripts ») et les feuilles de style (« src/scripts ») qui permettent d’assurer les fonctionnalités et l’aspect de toutes les pages du Mobiliscope. Ce dossier est compilé par webpack (en sortie les fichiers sont minifiés dans le dossier « dist ») afin de garantir un bon fonctionnement quelque soit le navigateur utilisé.
Cette section s’attache à décrire les fonctionnalités des pages de géovisualisation. L’essentiel des fonctions a été codé dans le fichier loads.js.
Les fonctionnalités de load.js
initGeovizMenu() : fonction qui définit le comportement et l’aspect du menu des indicateurs (pour rappel, geoviz_menu.php gère le contenu textuel et le balisage des éléments).
initLeafletMap() : fonction qui appelle les tuiles OSM à l’aide de la librairie leaflet.js, déclare le balisage des différents éléments de la carte (légende, source, échelle), redéfinit le control layers leaflet. Dans cette fonction, les couches d’habillage sont créées avec la librairie d3.js et la dépendance LD3SvgOverlay.js (carte d3 sur un fond leaflet).
initCodeSec() : fonction qui définit le secteur cliqué par défaut à l’arrivée sur une page de géovisualisation (prend codenamesec.json en entrée).
getShareInfo() : fonction pour le partage dynamique de la vue
loadGeoviz() : fonction qui définit le chemin dynamique vers les données stockées dans MinIO et qui lance la fonction de création des cartes et graphiques (cf. printMap() détaillées plus bas). Les arguments de cette fonction sont très importants : l’argument « idu » correspond à la clé unique de la donnée à afficher. Elle est définie à partir de trois éléments : l’indicateur, la modalité de l’indicateur et le mode de représentation (par exemple « age2_prop » correspond à la modalité « 2 » de l’indicateur « âge » calculé en nombre pour les cartes en cercles proportionnels). Pour une ville donnée, il existe autant de clé « idu » que de boutons (« % », « nb », « flow ») dans le menu des indicateurs. La clé est récupérée à chaque clic sur un bouton via le script geoviz_menu.php, de même que la couleur associée avec l’argument « col » (cf. infra).
load.js
// Chargement de la géoviz
function loadGeoviz(idu, col) {
if(isPlaying)
animateTimeline('off');
chemin = '/minio-ajax-loader.php?context=' + context + '&path=' + path + '&file=geo/' + idu +'.geojson';
printMap(chemin, idu, col) ;
}setLayerController() : fonction qui génère le contenu du control layers en fonction de la ville observée et du mode de représentation choisi. En effet, non seulement les fonds de carte et les couches d’habillage diffèrent d’une ville à l’autre mais l’ordre de superposition des couches n’est pas le même selon le mode de représentation. La gestion des superpositions est prise en charge par une matrice codée au début du script load.js (cf. infra). Dans la matrice, la suite de booléens simule les cases cochées dans le control layer (1 = cochée ; 0 = non cochée). Les valeurs associées à ces suites correspondent aux couches qui doivent être effectivement affichées lorsque la case est cochée. Et surtout, leur ordre d’apparition dans l’array correspond à leur ordre de superposition sur la carte.
load.js
// variables des layers
var layersControlVector = {'mmap':0,'muni':0,'mr':0,'tm':0, 'qp':0, 'zau':0, 'aav':0, 'acv':0, 'pvd':0};
// Extrait de la matrice - exemple de la superposition pour le mode "choro"
var layersControlMatrix = {
'choro':{
'000000000': [],
'100000000': ['mobiMap'],
// Amérique latine
'010000000': ['muniOverlay'],
'001000000': ['mrOverlay2', 'mrOverlay'],
'000100000': ['tmOverlay'],
'110000000': ['mobiMap', 'muniOverlay'],
'101000000': ['mobiMap', 'mrOverlay'],
'100100000': ['mobiMap', 'tmOverlay'],
'111000000': ['mobiMap', 'muniOverlay', 'mrOverlay'],
'101100000': ['mobiMap', 'tmOverlay', 'mrOverlay'],
'110100000': ['mobiMap', 'muniOverlay', 'tmOverlay'],
'011000000': ['mrOverlay2', 'muniOverlay', 'mrOverlay'],
'010100000': ['muniOverlay', 'tmOverlay'],
'001100000': ['mrOverlay2', 'tmOverlay', 'mrOverlay'],
'011100000': ['mrOverlay2', 'muniOverlay', 'tmOverlay', 'mrOverlay'],
'111100000': ['mobiMap', 'muniOverlay', 'tmOverlay', 'mrOverlay'],
// France
'100010000': ['mobiMap', 'qpvOverlay'],
'000010000': ['qpvOverlay'],
'100001000': ['mobiMap', 'zauOverlay1'],
'000001000': ['zauOverlay2', 'zauOverlay'],
'100011000': ['mobiMap', 'qpvOverlay', 'zauOverlay1'],
'000011000': ['zauOverlay2', 'qpvOverlay', 'zauOverlay'],
'100000100': ['mobiMap', 'aavOverlay1'],
'000000100': ['aavOverlay2', 'aavOverlay'],
'100010100': ['mobiMap', 'qpvOverlay', 'aavOverlay1'],
'000010100': ['aavOverlay2', 'qpvOverlay', 'aavOverlay'],
'000000010': ['acvOverlay'],
'100000010': ['acvOverlay', 'mobiMap'],
'100010010': ['acvOverlay', 'mobiMap', 'qpvOverlay'],
'000010010': ['acvOverlay', 'qpvOverlay'],
'000000001': ['pvdOverlay'],
'100000001': ['pvdOverlay', 'mobiMap'],
'100010001': ['pvdOverlay', 'mobiMap', 'qpvOverlay'],
'000010001': ['pvdOverlay', 'qpvOverlay'],
},
'prop':{
// ...
},
'flow':{
// ...
}
}Ces fonctions sont lancées par le controller (script src/scripts/controller.js). Le fichier view.js gère l’ouverture/fermeture du bloc des graphiques, l’arrêt de la timeline au clic dans le menu, ainsi que des exceptions concernant l’alignement des boutons du menu des indicateurs.
Focus sur la fonction printmap()
printMap() : fonction de création des cartes et de leur légende, des graphiques et de la timeline. Cette fonction s’appuie sur la librairie d3.js et de la dépendance LD3SvgOverlay.js qui permet le dessin des cartes d3 sur des tuiles leaflet (merci). Elle se subdivise en plusieurs fonctions :
displayGraphSegreg(): création du graphique affichant les indices de Duncan et de Moran. Prend en entrée les csv du dossier « segreg ».displayGraph(): création du graphique « secteur » affichant la modalité sélectionnée. Prend en entrée les csv du dossier « stacked ».stackedBarChart(): création du graphique « secteur » affichant l’ensemble des modalités d’un indicateur. Prend en entrée les csv du dossier « stacked ».displayMap(): création des cartes « Mobiliscope » et de leur légende. Prend en entrée les geojson du dossier « geo » ; pour le mode flow, prend également en entrée les csv du dossier « flowData ». La fonction s’appuie sur un if statement (if choro, prop ou flow) : selon le mode de représentation, la fonction ne lira que la partie du code concerné. Pour les légendes des cartes choroplèthes, la méthode de discrétisation et le nombre de classe sont déterminés en amont et définit en dur dans le code. En revanche, le calcul des bornes de classes est fait à la volée avec la librairie geostat.js (merci).createSlider()etanimate(): création de la timeline et de son animation.
Autres fonctionnalités importantes
Contrairement aux pages d’accueil et d’information, on ne trouvera aucun texte dans load.js. Tous les textes sont convertis en variables et centralisés dans le fichier translation.php du dossier « data-settings ».
La page de géovisualisation contient de nombreux pop-ups. Le contenu textuel de ces pop-ups sont également centralisés dans le fichier translation.php, tandis que leur fonctionnalité est codée dans le script popups.js du dossier « src/scripts ».
Les pages de géovisualisation contiennent par ailleurs un bouton help qui fonctionne comme un pop-up. Parce que ce bouton était placé en entête dans des versions précédentes du Mobiliscope, on trouvera le contenu de ce pop-up dans le fichier topbar.php de chaque dossier langue.
Enfin, le partage d’une vue particulière ne serait pas possible sans la fonction setUrlParam() codée dans le fichier get-param.js (toujours dans le dossier src/scripts). Cette fonction réécrit l’URL de la page de géovisualisation en y ajoutant les paramètres liés aux sélections d’heure, de secteur et de bouton cliqué dans le menu.
Les feuilles de style de la géovisualisation
Les styles des pages de géovisualisation se trouvent dans le dossier « src/styles » dans trois scripts préfixés « geoviz ». Les éléments de la page ont tous une propriété flexible (« flex ») afin de garantir le remplissage de la page (ordre d’apparition des éléments et proportion) quelle que soit la taille de l’écran et d’avoir une bonne responsivité sur les appareils mobiles.
geoviz-container.scss : css des différents containers de la page de géovisualisation. Ce fichier importe :
- geoviz-menu.scss : css du menu des indicateurs
- geoviz-map-charts.scss : css des cartes et graphiques
3.2 Versionnement du code
Le versionnement du code logiciel est assuré par l’utilisation d’un git : https://gitlab.huma-num.fr/mobiliscope/www.
À chaque mise en ligne, le commit correspondant à la version publiée est tagué afin de retrouver simplement les anciens états du code correspondant à chaque mise en ligne. Les tags sont formalisés avec la version du Mobiliscope et la date de publication (par exemple, v4_2_online_2023/06/15)
4 La préparation des données sous R
Le travail de préparation de données, réalisé sous R, est consultable sur le dépôt git dédié : https://gitlab.huma-num.fr/mobiliscope/data-process
Du point de vue géomatique, le travail est divisé en deux temps. Le 1er temps, décrit dans cette partie, est consacré aux traitements des données, le second temps à l’intégration des données dans le Mobiliscope (cf. Section 5 et Section 3).
Les données à traiter sont nombreuses, de différentes natures et construites pour différents usages. Il y a d’abord les bases de données alpha-numériques issues du résultat des enquêtes ménage-déplacement : les données brutes qui sont nettoyées, puis transformées en données de présence et enfin agrégées (cf. Section 4.1). Il y a aussi la base de données géographiques : les couches secteurs et zones fines sur lesquelles s’appuient les enquêtes ; les couches d’habillage à créer pour la géovisualisation (cf. Section 4.2). Il y a enfin toutes les autres données affichées dans les pages d’accueil et d’information (cf. Section 4.3).
Les traitements décrits dans cette partie ont été réalisés à partir de bases de données créées, enrichies et stockées localement dans un dossier nommé « 00_BD_mobiliscope » (cf. Fig 15). Pour reproduire les traitements, il faudra donc récupérer la BD (et les dictionnaires) déposée dans https://sharedocs.huma-num.fr, en accès privé. Dans sharedocs, la base est versionnée : le nom du dossier qui contient la BD porte la date de production des indicateurs dans le MinIO « test ». Par exemple, pour des données produites le 6 juillet 2023, la BD sera nommée « bd-source-20230706 ».

4.1 Les BD alpha-numériques
La préparation des données alpha-numériques suit trois grandes étapes
- de la BD brute à la BD clean : réception, nettoyage et prétraitements des données brutes des enquêtes ménage-déplacement
- En entrée : données brutes d’enquête (fichiers ménage, personne, déplacement, trajet)
- En sortie : BD_deplacement_clean.RDS et BD_personne_clean.RDS
- de la BD clean à la BD Présence : transformation des déplacements en présences
- En entrée : BD_deplacement_clean.RDS et BD_personne_clean.RDS
- En sortie : BD_presence.RDS et BD_presence_utile_ville.RDS
- de la BD Présence aux indicateurs : agrégation des présences par heure, secteur et modalité
- En entrée : BD_presence_utile_ville.RDS et bdgeo_v4-3.gpkg
- En sortie : geojson et csv lus par le Mobiliscope
4.1.1 Prétraitements sur la BD brute
Codes : data-process/prepa_bdnum/step1
La méthodologie des enquêtes déplacements, la structuration des données sources, la disponibilité de certaines informations varient d’un pays à l’autre. En France, les données sources peuvent également varier d’une ville à l’autre selon l’ancienneté, le producteur ou le distributeur. Ainsi, les prétraitements sont propres à chaque enquête et ont été réalisés à différents moments, sur une ville ou sur un ensemble de villes, au gré de la mise à disposition des données d’enquête. C’est pourquoi il n’existe pas un script unique reproductible pour l’intégration d’une nouvelle enquête dans la BD_clean.
Les scripts utilisés pour ces premières phases de traitements sont déposés dans le dossier « step1 » qui contient 3 sous-dossiers
- « france » : contient les traitements opérées sur 49 enquêtes de la base unifiée du Cerema (dans le dossier du même nom) et sur le dernier millésime de l’Enquête Globale Transport (dossier EGT2020).
- « canada » : contient les traitements opérées sur les enquêtes origine-destination du Québec - Canada
- « ameriquelatine » : contient les traitements opérées sur les 3 enquêtes sud-américaines.
Ces scripts, ainsi que les dictionnaires qui accompagnent la BD_mobiliscope, constituent la base à laquelle se référer si l’on souhaite connaître la manière dont a été construite la BD_clean.
les prétraitements de la BD_brute consistent à vérifier et à éventuellement apporter des corrections sur des incohérences des données brutes, à préparer les informations utiles au Mobiliscope en simplifiant, harmonisant, sélectionnant les variables d’interêt ou en en créant de nouvelles. L’objectif est d’obtenir une base harmonisée (autant que possible) qui compile toutes les enquêtes quels que soient leur date et leur pays de production. Cette base est constituée de deux tables : BD_personne_clean.RDS et BD_deplacement_clean.RDS
L’enquête la plus récemment intégrée à la BD_clean est celle de l’EGT2020.
Révision 1 : exploitation de la Base Unifiée du Cerema pour toutes les enquêtes françaises (hors EGT2020) ; révision des pré-traitements des enquêtes canadiennes (imputation des heures manquantes)
Révision 2 : ajout de la variable « composition du ménage » pour les enquêtes françaises et canadiennes ; redéfinition du dernier mode de transport principal pour le Canada
4.1.2 Création de la BD Présence
Codes : data-process/prepa_bdnum/step2
Lorsque les données brutes ont été nettoyées et prétraitées, il est possible de passer à l’étape suivante qui consiste en la création de la BD Présence à partir de la BD clean. Ce travail est réalisé avec les scripts d2p_fct.R et d2p.R
La BD Présence est constituée de plusieurs fichiers stockées au format .RDS. Elle se présente sous deux structures distinctes :
BD_presence.RDS : table qui compile toutes les présences individuelles (dans un secteur, dans un mode de transport ou hors périmètre) de toutes les enquêtes.
BD_presence_utile_[ville].RDS : pour chacune des 60 enquêtes, table des présences (dans un secteur) des 16 ans et plus (15 ans et plus pour le Canada), sans doublons et au format long.
BD_presence
La table des déplacements contient en creux les stations des individus (entre les lignes du tableau se lit leur présence en un lieu entre deux déplacements). La fonction d2p() récupère ces stations afin de construire une nouvelle table dans laquelle une ligne correspond à une présence individuelle en un lieu et sur une tranche horaire. À ces présences stationnaires, sont ajoutées les présences dans un mode de transport (codées dans un secteur fictif noté « 888 ») ainsi que les présences hors du périmètre d’enquête (codées dans un secteur fictif noté « 999 »), de sorte que, en sommant pour chaque individu la durée de ses présences, on obtient une journée complète de 1440 minutes. Une fois que les présences sont créées, on construit, à partir des intervalles de présence (hh:mm de début - hh:mm de fin), de nouvelles variables temporelles de type booléen (cf. infra). Enfin, on joint à la table des présences les variables socio-démographiques des individus contenues dans la table des personnes.
Principes de construction des présences
- Une présence dans une unité spatiale (secteur, zone fine, commune) débute à l’heure exacte où un déplacement prend fin et s’achève à l’heure exacte où un déplacement commence ;
- Toutes les présences sont incluses dans une journée type d’une durée de 24h, de 4h la veille du jour de passation de l’enquête à 4h le jour de passation de l’enquête. Les observations situées en dehors de cette fenêtre de 4h-4h sont supprimées ;
- Seuls les déplacements effectués un jour de semaine (lundi-vendredi) sont pris en compte ;
- Lorsque les individus se déplacent avec un mode de transport doux (piéton, vélo, roller etc.), leur déplacement est pris en compte comme une présence : la moitié du temps de déplacement est comptée comme présence dans la zone de départ, l’autre moitié est comptée comme présence dans la zone d’arrivée. Ainsi les individus qui se déplacent avec un mode doux sont pris en compte dans la population présente dans les secteurs où ils se déplacent, au contraire des déplacements effectués en mode motorisé (voiture, train, avion etc.).
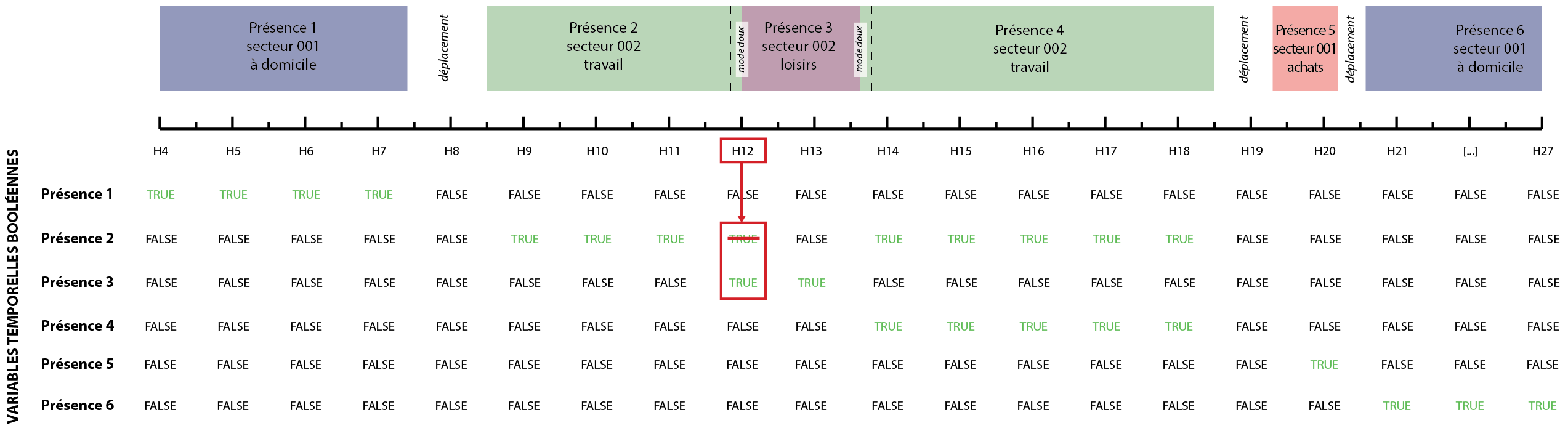
Principes de construction des variables temporelles de type booléen
- Les variables temporelles sont notées H4, H5, H6, […], H27, H4 valant 4h la veille de l’enquête et H27 valant 3h du matin le jour même de l’enquête ;
- De type booléen, elles permettent de définir heure par heure si une présence est vraie ou fausse et ainsi de sélectionner les observations lorsqu’on s’intéresse à chaque heure de la journée ;
- Pour qu’un individu ne soit compté qu’à un seul endroit pour une période d’une heure (même si au cours de cette période il est présent à plusieurs endroits), on fait le choix de ne prendre en compte que l’endroit où il se trouve à heure pile. Par exemple :
- Pour une zone donnée, une présence débutant à 10h00 et se terminant à 12h00 sera notée « TRUE » à H10, H11 et H12.
- Pour une zone donnée, une présence débutant à 10h00 et se terminant à 11h59 sera notée « TRUE » à H10 et H11 et sera notée « FALSE » à H12.
- Pour une zone donnée, une présence débutant à 10h01 et se terminant à 10h59 sera notée « FALSE » à H10 bien qu’elle recouvre quasi entièrement la tranche 10h00-10h59.
- Pour un individu donné, une présence débutant à 9h58 et se terminant à 10h03 sera notée « TRUE » à H10 tandis que la présence suivante de 10h10 à 11h30 sera notée « FALSE » à H10 bien qu’elle soit plus longue que la précédente dans la période 10h00-10h59.
NB : Si besoin dans le futur, le script bdm2presence_fct.R permet un changement peu coûteux des règles de codage des variables temporelles « H ». Par exemple, une prise en compte des présences sur une période de temps plutôt qu’à heure pile est possible en modifiant simplement une ligne de code :
##### code actuel
# Création d'un intervalle de référence pour chaque heure
# (les présences sont notées "TRUE" lorsqu'elles chevauchent l'intervalle de référence)
# Bornage de la journée
refDate <- ymd_hms("2010-01-01 04:00:00", truncated = 3)
refDate2 <- refDate + days(1)
## séquence de 24 heures
hInterval <- seq(refDate, refDate2, by = "hours")
## Intervalles de 0 minute : v1 = v2 (heure pile)
refHour <- data.frame(V1 = hInterval, V2 = hInterval) # ligne à modifier
## retrait de la 25eme heure
refHour <- refHour[1:24,]
## compute intervalle
refHour <- refHour %>%
mutate(REFINT = interval(V1, V2),
H = paste0("h", row_number()+3))
head(refHour[, 3:4]) REFINT H
1 2010-01-01 04:00:00 UTC--2010-01-01 04:00:00 UTC h4
2 2010-01-01 05:00:00 UTC--2010-01-01 05:00:00 UTC h5
3 2010-01-01 06:00:00 UTC--2010-01-01 06:00:00 UTC h6
4 2010-01-01 07:00:00 UTC--2010-01-01 07:00:00 UTC h7
5 2010-01-01 08:00:00 UTC--2010-01-01 08:00:00 UTC h8
6 2010-01-01 09:00:00 UTC--2010-01-01 09:00:00 UTC h9##### Modification de l'intervalle de temps de référence
## Par exemple, intervalles de 59 minutes
refHour <- data.frame(V1 = hInterval, V2 = lead(hInterval-1))
## retrait de la 25eme heure
refHour <- refHour[1:24,]
## compute intervalle
refHour <- refHour %>%
mutate(REFINT = interval(V1, V2),
H = paste0("h", row_number()+3))
head(refHour[, 3:4]) REFINT H
1 2010-01-01 04:00:00 UTC--2010-01-01 04:59:59 UTC h4
2 2010-01-01 05:00:00 UTC--2010-01-01 05:59:59 UTC h5
3 2010-01-01 06:00:00 UTC--2010-01-01 06:59:59 UTC h6
4 2010-01-01 07:00:00 UTC--2010-01-01 07:59:59 UTC h7
5 2010-01-01 08:00:00 UTC--2010-01-01 08:59:59 UTC h8
6 2010-01-01 09:00:00 UTC--2010-01-01 09:59:59 UTC h9
BD_presence_utile La BD_presence_utile est construite ensuite avec le même script à partir de la BD_presence avec la fonction createPrezLong(). C’est à partir de cette BD que sont créés les indicateurs. Ainsi, les tables qui la composent ne contiennent que les présences utiles à la géovisualisation. Les enquêté·e·s de moins de 16 ans (ou de moins de 15 ans pour le Canada) ont été supprimé·e·s. Les présences dans un mode de transport ou hors périmètre d’enquête ont été également supprimées, ainsi que les doublons de présence.
Au moment de la création des variables temporelles booléennes, des individus peuvent être comptés deux fois à heure H. Le cas se produit lorsqu’une présence se termine à heure pîle et que la suivante débute à cette même heure pîle. En principe, un temps de déplacement s’intercale entre deux présences dans un secteur, mais rappelons que les déplacements réalisés dans un mode doux (à pied, en fauteuil roulant, à vélo, etc.) ont été transformés en présence : la 1ère moitié de leur temps de déplacement est considérée comme présence dans le secteur d’origine (et avec le motif d’origine) ; la 2nde moitié comme présence dans le secteur de destination (et avec le motif de destination). Ainsi un déplacement fait à pied entre 11h55 et 12h05 sera compté comme présence dans le secteur d’origine jusqu’à 12h00 et compté comme présence dans le secteur de destination à partir de 12h. Les individus comptés deux fois à la même heure pîle dans dans deux secteurs distincts - ou dans un même secteur depuis la version 4.2 - sont détectés ; le choix de supprimer l’une ou l’autre de la ligne dupliquée est déterminé par la durée totale de la présence dans un secteur pour un motif donné : on supprime la présence à heure H qui débute ou achève le temps de présence le plus long, ceci afin de préserver au maximum les présences de courte durée (le déjeuner ou la course du midi entre deux temps longs de travail par exemple).
Pour l’enquête de Paris, 395 individus ont ainsi un double compte détecté (sur 26 312), pour Montréal 790 individus (sur 155 853) ont un double compte.
Par ailleurs, dans ces tables « utiles », certains codages de modalités diffèrent de la BD_presence car toutes les modalités ne sont pas retenues pour la géovisualisation. Celles qui ne sont pas retenues sont recodées 0 afin de faciliter le filtrage. Par exemple, la modalité 6 du motif des enquêtes françaises est recodée 0 car dans la géovisualisation, le motif de présence « autre » n’est pas représenté. Cette règle de filtrage générique engendre aussi d’autres recodages : la variable QPV qui est booléenne (0 et 1) est transformée en variable numérique (1 = non résident QPV et 2 = résident QPV) afin de garder l’ensemble des deux modalités.
Enfin, pour faciliter l’agrégation par heure/secteur/modalité, les tables de la BD présence utile sont au format long. Une ligne correspond à la présence d’un individu dans un secteur à heure H. On trouvera donc, pour chaque individu, au minimum une ligne et au maximum 24 lignes.
4.1.3 Création des indicateurs
On appelle « indicateur » la mesure/l’observation temporelle des différents groupes de population qui composent quotidiennement les quartiers et les communes. Il s’agit d’une quantité de population par heure et par secteur, population qui est qualifiée selon des critères socio-démographiques et qui est décrite en fonction de ses déplacements (mode de transport et motif de déplacement). En pratique, cela consiste à agréger (à sommer) la population contenue dans la table des présences par secteur, par heure et par modalité d’une variable considérée.
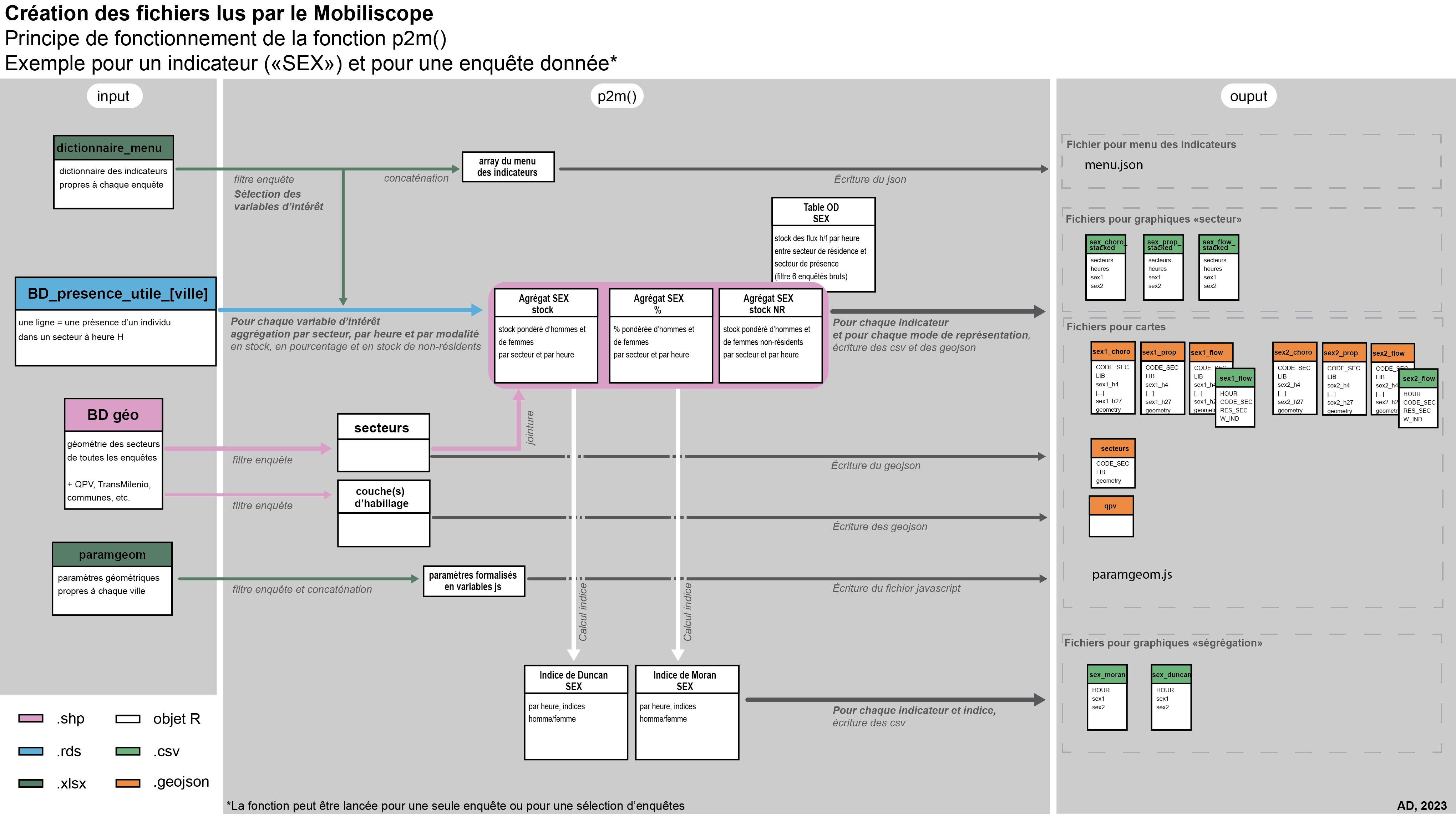
La préparation des indicateurs à intégrer au Mobiliscope est réalisé en amont avec les scripts p2m.R et p2m_fct.(https://gitlab.huma-num.fr/mobiliscope/data-process) :
- p2m_fct.R contient le code de la fonction
p2m(). Les fichiers en sortie sont écrits selon l’environnement spécifié : soit dans un dossier local, soit dans un MinIO local, soit dans un MinIO d’Huma-Num ;
- p2m.R est le script qui lance la fonction
p2m()stockée dans le fichier source p2m_fct.R
La fonction p2m() pour le Mobiliscope
Codes : data-process/prepa_bdnum/step3
La fonction prends 6 arguments en entrée : le nom de l’enquête (nomEnq), le chemin vers les données sources (cheminIn), le chemin vers l’espace de stockage des données créées (cheminOut), l’environnement (env) selon que l’on souhaite écrire les données en local (dossier windows ou MinIO) ou sur le MinIO d’Huma-Num ; les arguments perim et subpop sont toujours des listes vides et ne sont remplis que dans le cadre du Mobiliquest.
Pour la connexion avec MinIO, la fonction a besoin du fichier source miniovar.R qui contient les URL et logins. Pour des raisons de confidentialité, ce fichier est gitignoré.
p2m.R
p2m(nomEnq, perim = list(), subpop = list(), cheminIn, cheminOut, env)Pour chaque enquête, la fonction génère, à partir de la table des présences utiles correspondante, l’ensemble des fichiers csv et geojson nécessaires à la géovisualisation. Ces données sont stockées dans des dossiers qui portent le nom de l’enquête (i.e le nom de la ville qui a commanditée l’enquête) - cf. Fig 10
Le script p2m.R prévoit la sortie pour une seule enquête ou pour un ensemble d’enquêtes avec une boucle foreach() exécutée en calcul parallèle :
p2m.R
require(foreach)
require(doParallel)
Enq <- c('albi', 'santiago', 'saint-etienne')
foreach(i = Enq, .packages = myPck) %dopar% {
p2m(
nomEnq = i,
perim = list(),
subpop = list(),
cheminIn = cheminIn,
cheminOut = cheminOut,
env = "miniopreprod"
)
}À titre indicatif, en utilisant 5 cœurs, la sortie des fichiers pour l’ensemble des 60 enquêtes à notre disposition dure entre 1h30 et 2h.
La fonction p2m() dans le détail
La fonction p2m() encapsule d’autres fonctions qui ont chacune un rôle.
L’agrégation des présences individuelles par secteur et par heure et écriture des fichiers geojson et csv - fonction
createPopFiles():- densité de population totale (agrégat 1)
- population totale en nombre (agrégat 2)
- population totale non résidente en nombre (agrégat 3a)
- flux principaux secteur de présence / secteur de résidence (seuil à 6 répondants bruts) (agrégat 3b)
L’agrégation des présences individuelles par secteur, par heure et par modalité d’indicateur (sous-population) - fonction
prepPVS():- proportion de la sous-population (population de référence = somme des modalités de l’indicateur représentées dans le Mobiliscope) (agrégat 1)
- sous-population en nombre (agrégat 2)
- sous-population non résidente en nombre (agrégat 3a)
- flux principaux secteur de présence / secteur de résidence (seuil à 6 répondants bruts) (agrégat 3b)
Écriture des fichiers geojson et csv des sous-populations - fonction
createFiles()Calcul des indices de ségrégation (Duncan et Moran) et écriture des fichiers csv - fonction
createISeg()
La nature des données conditionne les modes de représentation cartographique. Ainsi, les données de rapport (agrégat 1) sont utilisées pour les cartes choroplèthes et leurs graphiques « secteurs » - mode « choro » ; les données de stock sont représentées dans les cartes en cercles proportionnels et leurs graphiques « secteurs » (agrégat 2 et 3a) - mode « prop » et « flow » ; les flux sont représentés par des lignes (de centroïde à centroïde) dont l’épaisseur varie selon le nombre de personnes pondérées (agrégat 3b) - mode « flow ».
Outre le calcul des agrégats et indices, la fonction p2m() renvoie d’autres données utiles à la géovisualisation :
menu.json : le fichier qui permet de construire le menu des indicateurs propre à chaque ville. La fonction
menuJson(), qui construit ce fichier, prend en entrée le dictionnaire du menu des indicateurs (cf. dictionnaire_menu.xlsx stocké dans la BD_mobiliscope/ressources)paramgeom.js : un fichier javascript qui stocke des variables propres à chaque ville. La fonction
paramgeom(), qui construit ce fichier, prend en entrée une feuille excel qui stocke des variables paramétrées ou formalisées manuellement pour chaque enquête (cf. paramgeom.xlsx stocké dans la BD_mobiliscope/ressources) .
Les deux fichiers dictionnaire_menu.xlsx et paramgeom.xlsx sont indispensables au bon fonctionnement du code R (et de l’application web). Leur modification et mis à jour doit se faire avec précaution. On les trouvera dans la BD_mobiliscope/ressources en #PrivateAccess (cf. Figure 15) . Pour les utilisateurs qui n’ont pas accès à la BD_mobiliscope, des fichiers exemples dictionnaire_menu_exemple.xlsx et paramgeom_exemple.xlsx sont librement mis à disposition dans le gitlab [data-process/meta]. Ces fichiers exemples (concernant uniquement la geoviz de Nantes et sa région) devrontt être adaptés à la nouvelle ville à ajouter (cf. Section 6.2)
Les couches d’habillage (qpv, communes, zonages) de la géovisualisation sont créées pour chaque ville par la fonction
otherLayers()encapsulée dans p2m().secteurs.geojson : la couche des secteurs (géométries, identifiants et libellés), d’une enquête donnée, fournie avec le téléchargement des données de présences agrégées, et issue de la BD géographique. Cette couche est créée avec la fonction
otherLayers().
L’ensemble de la chaîne de traitement de p2m() qui vient d’être décrit se retrouve schématiquement dans la Fig 17.
4.2 La BD géographique
Codes : data-process/prepa_bdgeo
La base de données géographiques est stockée au format GeoPackage qui contient l’ensemble des couches utiles au projet. Elle est accompagnée d’un fichier texte du même nom qui décrit son contenu.
#sf::st_layers("../../../00_BD_mobiliscope/BD_geo/bdgeo_v4-3.gpkg")La BD géographique a été réalisée avec le script 1_create_bdgeo_v4-3.R, à partir des couches auparavant stockées au format Shapefile. Les nouvelles couches d’habillage ont été préparée avec le script 2_create_newOverlays.R avant d’être intégrées à la bdgeo_v4-3.gpkg.
4.2.1 Les couches zones fines et secteurs
L’essentiel du travail réalisé sur les bases de données géographiques a consisté à produire des couches destinées à la géovisualisation du Mobiliscope à partir du maillage ad hoc des enquêtes ménage-déplacement. Celles-ci s’appuient sur deux échelles géographiques et statistiques : l’échelle des zones fines qui est le maillage le plus fin des enquêtes et qui correspond aux zones de collecte des origines et destinations des déplacements et au sein desquelles les ménages sont enquêtés ; l’échelle des secteurs qui est l’échelle d’analyse et de diffusion des résultats de l’enquête. Un secteur est entièrement couvert par une ou plusieurs zones fines et celles-ci ne sont pas nécessairement toutes enquêtées.
Les producteurs fournissent, avec les résultats des enquêtes, les couches SIG des zones enquêtées. En revanche, celles-ci ne sont pas standardisées (divergence de format, du nombre de couches, de système de projection géographique, de généralisation cartographique et surtout de qualité topologique et sémantique). Par ailleurs, certaines enquêtes ne disposent que d’une couche correspondant à un découpage en « zones fines » d’enquête c’est-à-dire à un échelon d’observation plus fin que celui des « secteurs » qui est la maille retenue pour l’agrégation et la diffusion des résultats dans le Mobiliscope. Dans ce cas, il a fallu créer la couche des secteurs à partir de la couche zones fines (par fusion de ces dernières). Pour certaines villes, des problèmes de topologie de la couche zones fines ont nécessité un nettoyage pour que les couches secteurs créées soit de bonne qualité.
Ce travail de nettoyage et d’harmonisation a débouché sur une base de données géographique unifiée pour l’ensemble des enquêtes françaises, canadiennes et sud-américaines. Elle est constituée de trois couches directement liées aux enquêtes :
- zf_50ed_w84 : l’ensemble des zones fines des 50 enquêtes françaises en WGS84 (pas de maillage en zones fines pour l’EGT IDF 2010)
- secteur_60ed_w84 : l’ensemble des secteurs des 60 enquêtes à notre disposition en WGS84
- perimetre_59ed_w84 : le périmètre de chacune des 59 enquêtes créé à partir des secteurs en WGS84 (le périmètre de l’EGT IDF 2020 est le même que celui de l’EGT IDF 2010)
À l’arrivée d’une nouvelle enquête, le même travail est à prévoir avant d’intégrer la nouvelle couche à la base géographique unifiée.
4.2.2 Les couches d’habillage
La BD contient par ailleurs les couches destinées à accompagner la géovisualisation des secteurs et qui apparaissent au clic dans le control layer :
Pour l’Amérique latine :
- comunas : la couche des communes incluses dans le périmètre des trois enquêtes latino-américaines
- metalrings : la couche des couronnes centre/périphérie (modalités simplifiées) construites dans le cadre du projet METAL
- transmilenio : la couche du tracé du TransMilenio (pour Bogotá)
Pour la France :
- qpv : la couche des Quartiers Prioritaires de la Politique de la Ville (à noter qu’il n’y a pas de QPV dans le périmètre d’Annecy)
- zau : la couche du Zonage en Aire Urbaine, Insee 2010 (modalités simplifiées)
- aav : la couche des Aires d’Attraction des Villes, Insee 2020
- pvd : la couche des communes bénéficiaires du Programme Ville de Demain (ANCT, 2023)
- acv : la couche des communes bénéficiaires de l’Action Coeur de Ville (ANCT, 2021)
4.2.3 Autres couches
- communes2021_49ed : communes françaises (géographie 2021) incluses dans le Mobiliscope
4.3 Autres données
Codes : data-process/prepa_autres_donnees
Les cartes et les indicateurs ne sont pas les seules données à construire pour le Mobiliscope. D’autres données sont à produire / mettre à jour pour assurer certaines fonctionnalités du site (par exemple le search) ou pour enrichir les pages d’information (par exemple le tableau synthétique des indicateurs).
4.3.1 Les données communales
Codes : data-process/prepa_autres_donnees/communes_secteurs
Dans le cadre de la réalisation d’une typologie des secteurs menée en partenariat avec l’ANCT, une nouvelle table des correspondances entre les secteurs et leurs communes d’appartenance a été produite (cf. la note méthodologique dans le dossier « communes_secteurs »). À la suite de ce travail, un certain nombre de fichiers utiles au Mobiliscope ont du être mis à jour.
Les libellés des secteurs
Pour les villes françaises, les secteurs correspondant à une ou plusieurs communes portent le nom de ces dernières. La mise à jour des libellés a été fait avec le script 1_libelles_secteurs.R. En sortie, on obtient le fichier LIB_SEC_59ED_V4-3.csv.
Ce fichier est ensuite converti au format json (2_codenamesec.R) et stocké aux côtés du code source du site web dans data-settings/codenamesec.json.
La couche des secteurs contient dans sa table attributaire les libellés des secteurs. Il est donc important de mettre à jour la BD géographique après chaque modification des libellés.
la liste des communes incluses dans le Mobiliscope
L’outil search du Mobiliscope fonctionne avec le fichier json town_list_autocomplete, également stocké dans le dossier www/data-settings. Il contient la liste de toutes les communes incluses dans le Mobiliscope associées à une enquête et à un secteur et permet de faire le lien entre la commune recherchée par l’utilisateurice et la page de géovisualisation, ainsi que le secteur où se trouve la commune. Ce fichier est construit avec le script 3_town_list_autocomplete.R
la base communes_secteurs pour diffusion
Dans ce même dossier communes_secteurs, on trouvera le script 4_prep_base_comsec_pour_diffusion.R qui a servi à mettre en forme les tables de correspondance des secteurs et des communes destinées à être diffusées.
4.3.2 Les tableaux des pages informations
Codes : data-process/prepa_autres_donnees/data_page_info
Les tables ACV et PVD
Les tables html des communes ACV et PVD incluses dans le Mobiliscope et qui apparaissent dans la page d’information “zoning.php” sont construites avec le script prep_acv_pvd_table.R.
La table QPV
La table html des QPV inclus dans le Mobiliscope appelée dans la dans la page d’information “zoning.php” est construite avec le script prep_qpv_table.R.
Les tableaux synthétiques des données d’enquête et des indicateurs
Les tableaux html des données d’enquêtes et des indicateurs sont préparés avec le script data_pageInfo.R.
4.3.3 La carte d’accueil
dossier : data-process/prepa_autres_donnees/carte_accueil
Les couches constituant les cartes sur la page d’accueil (cf. Figure 3) ont été construites sous QGis et sous R. Sous QGis, le travail est principalement vectoriel. Il s’agit d’une part de construire une couche des DOM « rapprochés » de la France métropolitaine et d’autre part de généraliser le tracé des contours des polygones. Sous R, le traitement des couches consiste à sélectionner/modifier/enrichir l’information attributaire, à créer les centroïdes des périmètres des enquêtes et à écrire l’ensemble des couches géographiques au format geojson (dans le dossier « 03_geojson2js »).
Pour optimiser le temps d’affichage des cartes d’accueil, les couches geojson sont transformées manuellement en variables javascript dans le script src/scripts/home-layers.js. Pour ce faire, pour chacun des fichiers du dossier « 03_geojson2js », il faut (1) ouvrir le geojson avec un éditeur (Sublime Text par exemple), (2) copier son contenu, (3) ouvrir le fichier scr/scripts/home-layers.js, (4) coller le contenu du geojson dans une variable javasrcipt (cf. infra).
Exemple de la variable javascript « fdGuyJson » stockant le geojson « fdGuy » correspondant au fond de carte pour la Guyanne française (c’est-à-dire le tracé des côtes des pays voisins) :
home-layers.js
var fdGuyJson = {
"type": "FeatureCollection",
"name": "fdGuy",
"crs": { "type": "name", "properties": { "name": "urn:ogc:def:crs:OGC:1.3:CRS84" } },
"features": [
{ "type": "Feature", "properties": { "id": 1.0 }, "geometry": { "type": "Polygon", "coordinates": [ [ [ -4.197397987968221, 44.534961225201279 ], [ -4.24336989664504, 44.488418935118474 ], [ -4.358092592965964, 44.26051917480104 ], [ -4.209684406145763, 44.037049523563894 ], [ -4.052927811017332, 43.917569730881759 ], [ -4.155414563730492, 43.583444311061584 ], [ -3.977348447700153, 43.553093831344569 ], [ -3.873796523808796, 43.633234395406539 ], [ -3.679434047339357, 43.662217880702549 ], [ -3.647188209646776, 43.619799607009014 ], [ -3.535798349801242, 43.627826868707082 ], [ -3.438134953879285, 43.725605243949524 ], [ -3.319318718661483, 44.075793799363332 ], [ -3.232318867162374, 44.252541689520839 ], [ -2.920550709579016, 44.089390270029931 ], [ -2.934502384544912, 44.009725383338761 ], [ -2.961745351968242, 43.931878975402689 ], [ -3.001823659161728, 43.857001628494942 ], [ -3.037962285985016, 43.805948491848234 ], [ -3.098461772174696, 43.738690210523409 ], [ -3.169671068258867, 43.677235454565214 ], [ -3.25051926626803, 43.622479671541171 ], [ -3.353173896068321, 43.569119695562705 ], [ -3.493967123863303, 43.517697275508816 ], [ -3.583495209188258, 43.495583830892244 ], [ -3.675654532563488, 43.480326062959421 ], [ -3.832436763082115, 43.470536154298451 ], [ -3.926792745124347, 43.474147241145687 ], [ -4.020142673462487, 43.484840780200173 ], [ -4.126460429052816, 43.506113011252005 ], [ -4.214262324995047, 43.5316654592866 ], [ -4.298002714709328, 43.563691280541406 ], [ -4.364034999422474, 43.595081144062704 ], [ -4.438032823663848, 43.638044217059075 ], [ -4.494785006372677, 43.67794856669915 ], [ -4.546609560321442, 43.721267552906539 ], [ -4.601737887286404, 43.777302478255301 ], [ -4.655549225944062, 43.847498650946292 ], [ -4.697260720754072, 43.921905567989945 ], [ -4.722876145501579, 43.988206057328981 ], [ -4.738801248832839, 44.056077199199557 ], [ -4.744616064697484, 44.147735638184848 ], [ -4.73730475686322, 44.216377320340676 ], [ -4.716188305306949, 44.295236851153618 ], [ -4.68177277717303, 44.371653226450356 ], [ -4.649298061247976, 44.424100724129687 ], [ -4.602011552422916, 44.48404612246226 ], [ -4.546127461403363, 44.540098090693675 ], [ -4.49341981333066, 44.583380187349555 ], [ -4.197397987968221, 44.534961225201279 ] ] ] } }
]
};4.3.4 Le bandeau violet (page d’accueil)
dossier : data-process/prepa_autres_donnees/banner_accueil
Le bandeau violet affiché dans la page d’accueil du Mobiliscope est construit avec Adobe Illustrator. Il varie selon le type d’appareil (ordinateur vs téléphone/tablette) et la langue.
5 Le Mobiliscope - Données
5.1 Organisation des données
Les données lues par le Mobiliscope ont été partitionnées en deux sous-ensembles :
- les données produites sous R (cf. Section 4.1.3) et structurées par ville sont stockées à part du code dans un bucket MinIO.
- les données globales - qu’elles soient constituées « à la main » ou issues d’un script R - sont stockées avec le code dans le dossier « data-settings » situé à la racine de https://gitlab.huma-num.fr/mobiliscope/www
Les données sont organisées à l’aide de clés de données uniques qui correspondent aux villes, aux indicateurs, aux modalités d’indicateurs ou aux modes de représentation.
5.1.1 Les données par ville
Les données des cartes et graphiques du Mobiliscope sont produites en amont sous R (cf. Section 4.1.3) dans l’optique d’être « prêtes à l’emploi » par l’application, sans transformation ou calcul à la volée en javascript. C’est pourquoi elles sont stockées dans une multitude de fichiers légers et organisés par ville, selon une structure identique (cf. Figure 18). Le nommage des fichiers de données s’appuie sur des clés uniques qui permettent de faire le lien entre l’indicateur et le mode de représentation sélectionnés dans le menu et les données à afficher.
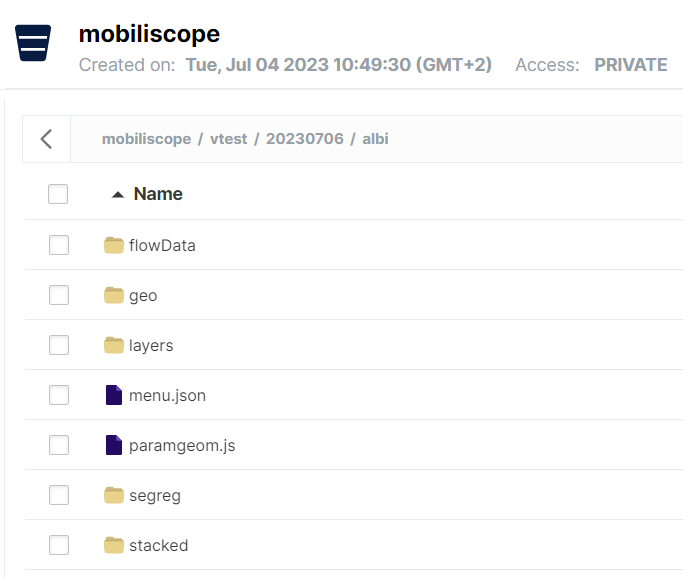
le dossier « stacked » contient les csv utilisés pour l’affichage des graphiques « secteur ». Il existe un fichier pour chaque indicateur et mode de représentation. Le nom des csv est constitué d’une clé « indicateur » et d’une clé « mode de représentation » de cette manière : ind_modrep_stacked.csv. Par exemple, le fichier act_choro_stacked.csv contient les données de présence, agrégées par secteur et par heure, pour chacune des modalités de l’indicateur « act » (lieux d’activité). Ce fichier est appelé lorsqu’on est sur des cartes choroplèthes (mode de représentation « choro ») et les valeurs sont affichées en pourcentage.
le dossier « segreg » contient les csv utilisés pour l’affichage des graphiques « région ». Il existe un fichier pour chaque indicateur et indice de ségrégation. Le nom des csv est constitué d’une clé « indicateur » et d’une clé « indice de ségrégation » (« duncan » ou « moran ») de cette manière : ind_segreg.csv. Par exemple, le fichier age_Duncan.csv stocke les indices de Duncan, calculés par heure, pour chacun des 4 groupes d’âge.
le dossier « geo » contient les geojson utilisés pour l’affichage des cartes. Il existe un fichier pour chaque modalité d’indicateur et chaque mode de représentation. Le nom des geojson est constitué d’une clé « modalité » et d’une clé « mode de représentation » de cette manière : modalité_modeReprésentation.geojson. Par exemple, le fichier act1_prop.geojson contient, outre les données géométriques des secteurs, les données de présence à domicile (« act1 » - modalité « 1 » de l’indicateur « act ») par secteur et par heure. Ce fichier est appelé pour les cartes en cercle proportionnel (mode de représentation = « prop ») et les valeurs sont donc stockées en nombre.
le dossier « flowData » contient les données utilisées par les cartes de flux. Il s’agit de tableau origine-destination destiné au dessin des flux entre secteur de présence et secteur de résidence. Il existe un fichier pour chaque modalité d’indicateur. Le nom des csv est formalisé de cette manière : modalité_flow.csv. Par exemple, le fichier act2_flow.csv contient les données concernant les personnes présentent sur leur lieu de travail (« act2 »).
le dossier « layers » contient les couches d’habillage au format geojson ainsi que la couche des secteurs vierge de toutes données de présence. Ce fichier ne sert pas à la géovisualisation mais il est fourni pour le téléchargement des données agrégées.
À la racine de chacun des dossiers « ville », on trouve deux fichiers supplémentaires, produits sous R en même temps que les fichiers décrits ci-dessus :
le fichier « menu.json » sert à la construction du menu des indicateurs (cf. geoviz_menu.php). Il stocke, pour une ville donnée, les différents niveaux du menu - groupes d’indicateurs, indicateurs, modalités et modes de représentation - à créer ainsi que les clés uniques, couleurs et labels associés.
le fichier « paramgeom.js » stocke des variables globales javascript propres à chaque ville. On y trouve la source des données d’enquête, les coordonnées pour centrer la projection (le plus souvent ajustées à la main), le code et label du secteur sélectionné par défaut, des paramètres d’affichage des légendes des cartes de stock.
5.1.2 Les données globales
Les fichiers décrits dans cette section sont communs à toutes les villes.
- readme.md : il s’agit du dictionnaire des variables qui est fournit avec le téléchargement des données agrégées. Il doit être mis à jour à chaque modification d’intitulés d’indicateur ou de modalité, et à chaque ajout ou modification de clé unique.
Les licences ODbL, également fournies avec le téléchargement des données agrégées, sont organisées en trois sous-dossiers « langue » : les licences ont été formalisées pour chacune des villes en français, en anglais et en espagnol (cf. Section 3.1.2). La mise à jour de ces dossiers se fait lors de la mise en prod d’une nouvelle version et du dépôt sur Zenodo des données correspondante (cf. Section 5.4).
city.php : ce fichier, construit manuellement, stocke la variable globale php
$cityqui est centrale dans le fonctionnement du Mobiliscope puisqu’il s’agit de la clé unique « ville » qui permet la redirection vers la page de géovisualisation d’une ville et de pointer vers le dossier de données correspondant (cf. Section 5.1.1). Cette clé prend le nom de la ville-centre des enquêtes ; elle ne doit comporter aucun espace ni caractère spécial. En revanche, grâce à la structure multidimensionnelle de cette variable, il est possible de décliner différentes formalisations pour une même clé (cf. infra), mais aussi de stocker d’autres informations propres à la ville comme le pays et la zone géographique d’appartenance.
city.php
// structure de $city - index sao-paulo
$city = [
'sao-paulo'=>[
'zoneGeo'=>'AS',
'ctry'=>'BR',
'shortName'=>'São Paulo',
'longName'=>[
'fr'=>'São Paulo et sa région',
'en'=>'São Paulo region',
'es'=>'São Paulo y su región',
],
'htmlName'=>[
'fr'=>'São Paulo <small>et sa région (2017)</small>',
'en'=>'São Paulo <small>region (2017)</small>',
'es'=>'São Paulo <small>y su región (2017)</small>',
],
],
];
- translation.php : ce fichier, également construit à la main, stocke l’ensemble des textes - et leur traduction - qui apparaissent dans les pages de géovisualisation. Il s’agit d’un array multidimensionnel. Le niveau zéro distingue les textes appelés en javascript (« frontTranslation ») des textes appelés en php (« backTranslation »).
Structure de frontTranslation :
Pour les textes qui ne varient que selon la langue, l’index du 1er niveau prend le nom de la variable javascript et le 2e niveau contient trois éléments indexés “fr”, “en” et “es”.
translation.php
// Exemple de texte simple stocké dans frontTranslation
$translation = [
"frontTranslation" =>[
// ...
'titleGraph1' => [
"fr" => "DANS L'ENSEMBLE DE LA RÉGION",
"en" => 'IN THE WHOLE REGION',
"es" => 'EN TODA LA REGIÓN'
],
// ...
],
// ...
]Pour les textes qui ne varient pas seulement selon la langue, mais également selon la modalité ou le mode de représentation, on utilise un niveau supplémentaire : l’index du 1er niveau prend le nom de la variable javascript, le 2e niveau correspond à une clé de donnée unique et le 3e niveau correspond à la langue.
translation.php
// Exemple de titre de carte variant selon la modalité sélectionnée
$translation = [
"frontTranslation" =>[
'tMap' =>[
// GLOBAL
'pop0' => [
"fr" => 'Population <strong>totale</strong> présente',
"en" => '<strong>Total</strong> ambient population',
"es" => 'Población <strong>total</strong> presente'
],
// ...
],
// ...
],
// ...
]
Structure de backTranslation :
Cette dimension est réservée aux textes du menu des indicateurs (qui sont intégrés via une boucle codée dans geoviz_menu.php). Le 1er niveau correspond à une clé unique renvoyant soit à un groupe d’indicateurs, soit à un indicateur, soit à une modalité. Le 2e niveau correspond aux langues.
translation.php
// 1ères lignes de $translation["backTranslation"]
$translation = [
// ...
"backTranslation" =>[
// GLOBAL
"global" => [ // groupe d'indicateur
"fr" => 'GLOBAL',
"en" => 'GLOBAL OVERVIEW',
"es" => 'GLOBAL',
],
"pop" => [ // indicateur
"fr" => 'Population totale',
"en" => 'Whole population',
"es" => 'Población total',
],
"pop0" => [ // modalité
"fr" => 'Population totale',
"en" => 'Whole population',
"es" => 'Población total',
],
// ...
],
]- colors.js : ce fichier comporte deux variables globales javascript écrites à la main. La variable ‘colors’ stocke dans un array à deux dimensions l’ensemble des nuanciers des cartes choroplèthes ; l’index correspond aux clés uniques des modalités (variable js « indmod »). La variable « gamme » est réservée aux popups du menu des indicateurs. Elle ordonne pour chaque indicateur l’ensemble des couleurs des modalités ; l’index correspond aux clés uniques des indicateurs (variable js « ind »)
Les deux fichiers suivants sont issus d’un traitement R. Ils ne doivent pas être modifiés à la main et sont à mettre à jour au moment de l’intégration d’une nouvelle enquête.
codenamesec.json : liste des secteurs (codes et libellés) (cf. Section 4.3).
town_list_autocomplete.json : liste de toutes les communes incluses dans le Mobiliscope associées à une enquête et à un secteur et permet de faire le lien entre la commune recherchée par l’utilisateurice et la page de géovisualisation, ainsi que le secteur où se trouve la commune (cf. Section 4.3).
5.2 Versionnement des données par ville dans MinIO
Dans le MinIO « test » correspondant au développement en équipe ou à la pré-production, comme dans le MinIO « production » réservé aux données du Mobiliscope public, on trouve le bucket « mobiliscope » qui contient les données par ville utilisées par la géovisualisation.
Ces deux MiniOs sont installées sur la machine HumaNum (montage NFS de 150 Go pour stocker les données des 2 minio)
Le versionnement des données dans MinIO s’appuie sur le nommage des objets/dossiers. On trouvera à chaque fois un numéro de version et la date de production des données.
Ci-dessous, schéma d’organisation des données du bucket « mobiliscope », avec l’exemple de deux jeux de données :
- Un jeu de données en date du 5 septembre 2023 [20230905] utilisé en dev/pre-prod
- Un jeu de données en date du 10 juillet 2023 [20230706] utilisé en prod (v4.3) - et qui était en dev/pre-prod auparavant
Bucket « mobiliscope » du minio Test
Ce bucket sert au dev ET à la preprod. On choisit de garder l’historique des données utilisées en dev ET en preprod. Si trop de folders, on pourra imaginer à terme une sauvegarde externe.
[vtest]
- [20230905]
- [ville1]
- [ville2]
- …
- [20230706]
- [ville1]
- [ville2]
- …
- [20230905]
Bucket « mobiliscope » du minio de prod
Ce bucket sert uniquement à la prod
- [v4-3]
- [20230706]
- [ville1]
- [ville2]
- …
- [20230706]
5.3 Procédure d’intégration de données dans MinIO
Les grandes ETAPES pour préparer par exemple une version des données en date du 6 juillet 2023
5.3.1 Etape 1. Sauvegarde BD source
S’assurer que toutes les données des folders [BD_brute], [BD_clean], [BD_geo], [BD_presence], [BD_presence_mobimama], [BD_presence_utile] et [ressources] sont à jour.
Déposer dans ShareDocs (https://sharedocs.huma-num.fr/#/HOME/Mobiliscope) une copie du dossier (volume zippé : 2.4 Go) dans lesquelles se trouvent toutes ces données et l’appeler [bd-source-20230706]. (dépôt accessible via login HumaNum #PrivateAccess)
5.3.2 Etape 2. Préparation des données Mobiliscope dans le minio TEST
Dans le script p2m.R (cf. gitlab [data-process/prepa_bdnum/step3]), renseigner le chemin de sortie avec la bonne date, c’est-à-dire [mobiliscope/vtest/20230706] dans le minio TEST HumaNum
Lancer le script p2m_fct.R (=> écriture des données dans [mobiliscope/vtest/20230706] du minio TEST HumaNum.)
Commiter le script p2m.R (cf. gitlab [data-process/ prepa_bdnum/step3] et taguer le commit [20230706]. Avec ce tag, on pourra revenir à tous les scripts de data-process ayant servi à faire les données contenues dans [bd-source-20230706]
5.3.3 Etape 3. Mise en prod
Si les données du 6 juillet 2023 sont utilisées pour la prod de la version [v4-3]
Télécharger le contenu de [mobiliscope/vtest/20230706] du minio de test sur votre ordi, le dézipper et l’uploader ensuite dans le [mobiliscope/v4-3/20230706] du minio de prod. (Plutôt que télécharger/dezipper/uplaoder, on peut aussi utiliser la commande mc cp)
Déposer en open-data sur Zenodo un extrait des données contenu dans le bucket [mobiliscope/v4-3/20230706] du minio PROD HumaNum
5.3.4 Etape 4 : En cas de mise à jour ultérieure des données sources
Si mise à jour de la [bd-source] sauvegardée dans sharedocs (par exemple parce que de nouvelles villes ont été ajoutées et/ou que le script R de création des tables de présences utiles (d2p.R/d2p_fct.R) a changé)
ou si mise à jour des données mobiliscope dans minio, par exemple parce que le script R de sortie des données (p2m_fct.R) a changé
=> refaire tout le process (étapes 1 à 3)
5.4 Dépôt des données en open-data sur Zenodo
Pour chaque version de prod du Mobiliscope, il existe un dépôt Zenodo identifié par un DOI (Digital Object Identifier). Ce dépot zenodo contient les données stockées dans le minio (à l’exception des données stockées dans le dossier flowData), ainsi que (1) un dictionnaire des données (le readme.md (cf. [www/data-settings]) ; (2) les fichiers pdf résumant les termes de la licence ODbL (cf. [www/data-settings/odbl]).
A partir de la v4-3, le dépôt Zenodo compile donc toutes les données téléchargeables via la géovisualisation mais plus largement celles nécessaires pour faire fonctionner le Mobiliscope.
Remarque: Il est possible d’uploader dans son minio local les données en open-data issues du dépôt Zenodo. cf. Section 2.6
Les étapes à suivre pour faire le dépôt Zenodo :
5.4.1 Etape 1. Réserver un nouveau DOI
Se connecter à Zenodo / Mobiliscope : https://zenodo.org/doi/10.5281/zenodo.3628713 (#PrivateAccess)
Cliquer sur New Version
Choisir l’option : Reserve a DOI by pressing the button (so it can be included in files prior to upload). The DOI is registered when your upload is published
Sauvegarder le nouveau DOI
5.4.2 Etape 2. Utiliser ce nouveau DOI
Ce nouveau DOI doit être indiqué dans :
les 4 pages infos (cite ; evolution; license; opendata) et le footer (footer.php) dans les 3 langues
le fichier readme stocké dans www/data-settings
les fichiers de licence odbl
ouvrir les fichiers .docx en 3 langues (stockés dans dans le dossier : data-process/prepa_autres_donnees/prepa_opendata/licence-odbl) pour y ajouter le DOI réservé sur Zenodo et enregistrer les fichiers en .pdf
Copier ces 3 pdf dans le sous-dossier [odbl] du dossier « data-settings » situé à la racine de https://gitlab.huma-num.fr/mobiliscope/www
5.4.3 Etape 3. Sélectionner les données minio
Principe : On veut garder toutes les données stockées dans le minio, sauf le sous-dossier [flowMap] de chacune des villes car les infos de ce sous-dossier posent des problèmes de confidentialité
Remarque : On met aussi les data pour Valenciennes2011 [valenciennes2011] et Paris2020 [idf2020]
Télécharger le contenu du minio (de prod ou de test) que l’on souhaite copier, le dézipper et nommer le dossier [20230706]
Créer un dossier qui recevra les données à mettre en open data, par exemple [20230706opendata]
Dans le dossier [20230706open], ajouter le fichier .rcj des exceptions. Le modifier (et le renommer) si besoin en fonction des fichiers/dossiers que l’on ne veut pas copier. Ce fichier .rcj est stocké dans data-process/prepa_autres_donnees/prepa_opendata/robocopy
Facultatif : pointer dans le dossier [20230706open] (utile si espaces dans le chemin vers le dossier)
cd D:\Documents\Mobiliscope\Zenodo\20230706opendataCopier tout le dossier issu du minio [20230706] dans le dossier [20230706opendata], sauf les exceptions notées dans le fichier except-data-v4-3.rcj
robocopy D:\Documents\Mobiliscope\Minio\minio-test\mobiliscope\vtest\20230706 D:\Documents\Mobiliscope\Zenodo\2024_11_06_v4.3_OpenData\20230706opendata /S /job:D:\Documents\Mobiliscope\Zenodo\2024_11_06_v4.3_OpenData\20230706opendata\except-data-v4-3syntaxe :
robocopy Source_folder Destination_folder [files_to_copy] [options]source : https://ss64.com/nt/robocopy.html
Faire une copie du fichier .rcj des exceptions dans dans data-process/prepa_autres_donnees/prepa_opendata/robocopy. Supprimer fichier .rcj des exceptions du dossier [20230706opendata].
On peut uploader tout ce dossier [20230706opendata] dans son minio local pour vérifier qu’un utilisateur externe pourra bien l’utiliser pour installer le Mobiliscope en local sur son ordi. cf. Section 2.6. Attention il ne faut pas d’espace ou de “_” dans le nom du dossier
5.4.4 Etape 4. Préparer les autres données dans le dossier à déposer dans Zenodo
Au même niveau que le dossier [20230706opendata] - et donc pour nous dans D:\Documents\Mobiliscope\Zenodo\2024_11_06_v4.3_OpenData :
Ajouter les 3 pdf odbl stockés dans www/data-settings/odbl»
Ajouter le fichier readme.md stocké dans www/ data-settings. Ce readme contient un dictionnaire de données mais aussi le lien vers le guide admin (et la section #sec-dataville), avec des infos dans les 3 langues.
5.4.5 Etape 5. Faire le dépôt
Zipper le dossier [20230706opendata] et déposer le zip dans la new version Zenodo avec le doi reservé.
Ajouter aussi les 3 pdf odbl et le fichier readme.md
Mettre en Visibility Restricted et Comme ‘default preview’, cocher le fichier “readme.md”
Renseigner les metadata (on pourra les modifier ensuite). Indiquer que les données de ce dépôt
- is part of : mobiliscope.cnrs.fr
- is documented by : guide admin
- is derived from : git data-process
- is required by : git www
Cliquer sur publier (Attention : les fichiers déposés ne pourra plus être modifié une fois le dépôt publié - et aucun autre fichier ne pourra être ajouté).
Passer le dépôt en Visibility Public lorsque la version correspondante du Mobiliscope est mise en prod.
6 Mise à jour du Mobiliscope
6.1 Ordre exécution des scripts pour les données avec la bu2023 (version v4.4)
N°1 data-process\prepa_bdnum\step1\france\cerema_bu2023
1_bd_pers_nice_corrigee.R
2_bdu2bdm.R
Note pour intégration nouvelle ED :
*Mettre à jour correspondance_IDM4.csv dans step1*\france\cerema*_bu2023*\txt
Vérifier les heures de départ et d’arrivée des déplacements dans 2_bdu2bdm.R et corriger en cas d’erreurs (~ligne 1082)
N°2 data-process\prepa_bdgeo
4_upd_bdgeo_bu2023.R
5_filter_bdgeo_oldperim.R (Pour ville avec enquêtes multidates & périmètres géo différents)
Note pour intégration nouvelle ED : dans 4_upd_bdgeo_bu2023.R
Faire au préalable sur QGIS une vérification visuelle des shape (quelle verif ?)
Vérifier la validité des géométries des différents shape (cf. script) ;
Pour les nouveaux périmètres, secteurs et zf, s’assurer qu’on a bien entré toutes les infos pour les variables prédéfinies dans le script (verificaton manuelle)
N°3 data-process\prepa_autres_donnees\communes_secteurs
0_communes_secteurs_zonages.R
1_libelles_secteurs.R
2_codenamesec.R
3_town_list_autocomplete.R
4_prep_base_comsec_pour_diffusion.R
Note pour intégration nouvelle ED :
- dans 0_communes_secteurs_zonages.R (partie I), veuillez supprimer le maximum de résidus crées par l’intersection (~ligne 133).
N°4 data-process\prepa_bdgeo
- 6_upd_overlay.R
N°5 data-process\prepa_bdnum\step1\france\cerema_bu2023
3_zonage_residentialArea.R
4_qpv.R (! un peu long)
5_filter_oldperim.R (Pour ville avec enquêtes multidates & périmètres géo différents)
N°6 data-process\prepa_bdnum\step1
- join_bd_clean_all_cities.R
N°7 data-process\prepa_bdnum\step2
- d2p.R et d2p_fct.R (! un peu long, surtout présence utile - Faire d’abord enquêtes FR puis ensuite enquetes non FR)
N°8 data-process\prepa_bdnum\step3
p2m.R et p2m_fct.R
Note pour intégration nouvelle ED :
- avant de faire tourner step3, mettre à jour les 2 fichiers paramgeom.csv et dictionnaire_menu (dans bd-source-2025/ressources)
- SI CHANGE OLD PERIM faire 3 changements dans p2m_fct (rechercher “SI CHANGE OLD PERIM”)
N°9 data-process\prepa_autres_donnees\data_page_info
tableaux_synthetiques : data_pageInfo.R
acv_pvd: prep_acv_pvd_table.R
qpv : prep_qpv_table.R
6.2 Intégration d’une nouvelle ville étape par étape
6.2.1 Étape 1. Traitements des données
Mise à jour de la BD_clean : prétraitements sur la BD brute en vue d’une intégration des déplacements et des personnes dans la BD clean / mise à jour du dictionnaire BD_clean_dico.xlsx (Section 4.1.1)
Mise à jour de la BD géographique et de son dictionnaire : prétraitements sur la couche des secteurs (et éventuellement des zones fines). Création du périmètre de l’enquête, des couches d’habillage (Section 4.2).
Ces deux premières étapes incluent la création de variables qui n’existent pas nécessairement dans les données brutes : résidence en QPV ; résidence selon le ZAU simplifié en 3 modalités ; libellés des secteurs (pour une nouvelle enquête française, nécessite de réaliser un travail sur les correspondances commune/secteur) etc. Prévoir des allers-retours entre ces deux premières étapes.
Mise à jour de la BD présences : faire tourner le script d2p.R pour sortir les présences à partir de la BD clean / mise à jour des dictionnaires (Section 4.1.2)
Création des indicateurs (Section 4.1.3)
Mise à jour des fichiers dictionnaires_menu.xlsx et paramgeom.xlsx.
Faire tourner le script p2m.R (dans un premier temps, écriture des données dans son MinIO local). Ce script prend impérativement en entrée les données suivantes
- presence_utile_[ville].RDS
- bdgeo_v4-3.gpkg : couche secteur et les couches d’habillage
- dictionnaires_menu.xlsx
- paramgeom.xlsx
Prévoir la mise à jour de la fonction otherLayers() dans p2m_fct.R (et dans p2m_fct.R dans le dépôt git du mobiliquest) pour inclure les couches d’habillage associée à la nouvelle ville.
6.2.2 Étape 2. Intégration des données
data-settings/city.php : ajout « à la main » de la clé « ville » unique de la nouvelle géovisualisation ainsi que ses diverses formalisations (Section 5.1.2).
load.js, modification du « form » dans le control layers (var lc) pour inclure les couches d’habillage associées à la nouvelle ville (Section 3.1.3).
Ces interventions suffisent à obtenir une géovisualisation fonctionnelle, qu’il faut tester attentivement afin de repérer d’éventuelles incohérences dans les données ou dysfonctionnements techniques. La suite concerne des fonctionnalités non vitales au bon fonctionnement des cartes et graphiques et la production d’informations complémentaires.
6.2.3 Étape 3. Mise à jour des données complémentaires
codenamesec.json et town_list_autocomplete.json : fichiers utilisés par l’outil search, à modifier via les scripts R du même nom. Pour les villes françaises, nécessite d’avoir réalisé un travail sur les correspondances commune/secteur.
bandeau violet : mise à jour des chiffres-clés dans le bandeau violet.
licence ODbL (pdf) : mise à jour du tableau avec la source des données de la nouvelle ville (et avec le DOI zenodo correspondant au nouvelle base de données déposée en open data. cf. Section 5.4)
carte d’accueil : mise à jour du fichier home-layers.js.
data_table.html et indicators_table.html : il s’agit des tableaux synthétiques des pages « data » et « indicators » du site, à mettre à jour via le script data_pageInfo.R
acv_table.html, pvd_table.html : il s’agit des tableaux de la page d’info « zoning », à mettre à jour via le script prep_acv_pvd_table.R. Nécessite un travail sur les correspondances commune/secteur
qpv_table.html pour les villes françaises : il s’agit du troisième tableau de la page d’info « zoning », à mettre à jour via le script prep_qpv_table.R.
Pour cette 3ème étape, voir la Section 4.3.
Une fois qu’on est bien sûr de ses données et de sa nouvelle géovisualisation, on peut passer aux étapes suivantes qui consistent à mettre à disposition l’ensemble des données aux membres de l’équipe.
6.2.4 Étape 4. Mise à jour des données sur le bucket mobiliscope du MinIO Test d’Huma-Num
Refaire tourner le script p2m(), cette fois pour l’ensemble des enquêtes et en choisissant l’écriture dans le MinIO-test distant
Commiter le script p2m.R et taguer le commit avec la date de production des données
6.2.5 Étape 5. Pour la mise en PROD
Télécharger les nouvelles données du minio de test sur votre ordi, le dézipper et l’uploader ensuite dans le minio de prod.
Déposer en open-data sur Zenodo un extrait des données contenu dans le bucket [mobiliscope/v4-3/20230706] du minio PROD HumaNum
6.3 Création de nouveaux indicateurs
Exemple de l’ajout du zonage d’appartenance des secteurs canadiens (zone urbaine/périphérique). Cette information, une fois construite, doit être stockée dans deux bases de données
- dans la base de données géographiques (BD_geo) : dans la table attributaire de la couche unifiée des secteurs (qui compile les secteurs de toutes les enquêtes en wgs84)
- mais également dans la BD_clean : dans la table BD_personne_clean.RDS afin d’avoir l’information “zonage de résidence” des personnes enquêtées
Pour cela, il faut une table de correspondance entre les secteurs et leur zonage, avec une clé de jointure correspondant aux identifiants uniques des secteurs (ID_SEC : nom enquête, date enquête, code secteur).
6.3.1 Étape 1. Mise à jour des bases de données
BD_clean : Pour la mise à jour de la table BD_personne_clean.RDS, nous recommandons l’écriture d’un nouveau script dans data-process/prepa_bdnum/step1 et de se référer au dictionnaire BD_clean_dico.ods (cf. Section 4.1.1)
- appeler en entrée la BD_personne_clean.RDS
- créer la clé de jointure ID_SEC : ENQUETE_DATE_RES_SEC (code du secteur de résidence)
- joindre le zonage de la table de correspondance par ID_SEC
- écraser l’ancienne BD_personne_clean.RDS avec la mise à jour
Attention de ne pas écraser les données de zonage francaises et sud-américaines pendant le process, ou tout autre donnée existante. Penser à mettre à jour le dictionnaire. Stocker la table de correspondance à côté de ce script.
BD_geo : le script data-process/prepa_bdgeo/3_upd_secteurs.R peut être utilisé pour joindre le zonage des secteurs à la couche des secteurs. Il contient d’ailleurs le recodage en toutes lettres des modalités des zonages français et sud-américaines. Il faudra faire de même pour le zonage canadien. Attention de ne pas écraser les modalités de zonage existantes. Penser à mettre à jour également le dictionnaire bdgeo_v4-3.txt (cf. Section 4.2).
Mise à jour de la BD_presence et de la BD_presence_utile (cf. Section 4.1.2)
- dans data-process/prepa_bdnum/step2/d2p_fct.R, ligne 422, ajouter la variable ZONAGE (cette partie de la fonction sélectionne les variables utiles pour chaque table presence_utile_[ville].RDS).
- faire tourner le script d2p.R pour sortir les présences à partir de la nouvelle BD clean. Mettre à jour les dictionnaires
Mise à jour des fichiers lus par le Mobiliscope (cf. Section 4.1.3)
dans la BD_mobiliscope/ressources : mettre à jour le fichier dictionnaire_menu.xlsx. Il s’agit d’un fichier source de la fonction p2m(). Il sert à la fois pour la construction des fichiers menu.json et pour la sélection des variables à sélectionner pour la création des indicateurs.
Dans l’onglet « CA », ajouter les lignes correspondantes au nouvel indicateur, en suivant la logique de ce qui est déjà renseigné. Dans la table des présences, la VARIABLE s’appelle ZONAGE pour toutes les enquêtes. Mais, à cette étape de passage des variables aux indicateurs, il est nécessaire de changer de nom, pour garantir des clés de données uniques, d’autant que cette information contient des exceptions selon le pays d’origine des enquêtes. Pour information, pour la France on a INDICATEUR « resarea » et pour l’Amérique du sud, « zona ». Pour la colonne «COL», on pourra utiliser les mêmes couleurs utilisées pour les villes françaises.faire tourner le script p2m.R : dans un premier temps, écriture des données des 6 villes canadiennes dans son MinIO local
6.3.2 Étape 2. Modification du code source
fichier www/data-settings/translation.php : ajouter les textes du nouvel indicateur associés à leurs clés uniques (faire une recherche dans le document de « resarea » ou « zona » et suivre le modèle de ce qui a été fait) - cf. Section 5.1.2.
fichier www/data-settings/colors.js : ajouter les nuanciers de couleurs pour les cartes choroplètes (les nuanciers utilisés pour le zonage français peuvent très bien servir ici) et les teintes associées à chacune des modalités pour la mise en couleur du pop-up de l’indicateur - cf. Section 5.1.2.
fichier src/scripts/view.js : adapter les exceptions concernant l’alignement des boutons du menu des indicateurs - cf. Section 3.1.3.
admirer la géovisualisation
6.3.3 Étape 3. Mise à jour des données MinIO
Refaire tourner le script p2m(), cette fois pour l’ensemble des enquêtes et en choisissant l’écriture dans le MinIO-test distant.
Commiter le script p2m.R et taguer le commit avec la date de production des données
Pour la mise en PROD:
Télécharger les nouvelles données du minio de test sur votre ordi, le dézipper et l’uploader ensuite dans le minio de prod.
Déposer en open-data sur Zenodo un extrait des données contenu dans le bucket [mobiliscope/v4-3/20230706] du minio PROD HumaNum
7 Modifications/actualisations à envisager
Prévoir la mise à jour de d3.js avec une version récente (actuellement utilisation de la v3) et refactorisation de la fonction
printMap()dans load.jsChanger des titres : dans translation.php
Changer le seuil d’âge (par exemple passer de 16 ans et plus à 15 ans et plus) : modifier la fonction
createPrezLong()dans le script d2p_fct.R qui sélectionne la population de référence dans le Mobiliscope ; refaire tourner le script d2p() puis le script p2m() ; modifier les textes (titres, pop-ups, etc.) qui mentionnent le seuil d’âge minimum dans translation.php et dans les pages d’information.Construire une base correspondance avec les IRIS => piste à prévoir via une interpolation spatiale ?
Fonctionner avec un système de dockers/containers - envisagé en lien avec le Mobiliquest (cf. Section 8).
Ajouter page “politique de confidentialité” qui comporte les infos suivantes: la donnée (donc dans ce cas, un cookie de matomo) ; la finalité; le temps de rétention; la personne responsable de la donnée. Proposer un opt out dans cette page, pour laisser l’utilisateur sortir du tracking, Matomo propose un code dans son interface à coller dans la page. (cf. Section 2.7).
Cf. aussi la roadmap du Trello https://trello.com/w/mobiliscope (#PrivateAccess)
8 L’outil Mobiliquest - Under progress
Cet outil est pour l’instant under progress.
Le Mobiliquest est un outil de requêtage permettant d’extraire d’autres données agrégées de présence que celles affichées dans le Mobiliscope classique “grand public”. L’idée est de stocker les data issues de la requête dans un répertoire sur le serveur (comme c’est déjà le cas sur le Mobiliscope) . A terme, il pourrait être envisagé d’afficher sur le Mobiliscope les nouvelles données générées.
8.1 Les deux requêtes
Le Mobiliquest propose des requêtes aux utilisateurs “experts” sans avoir à pré-calculer tous les résultats à l’avance. Le Mobiliquest propose deux requêtes : la requête [SUBPOP] et la requête [PERIM].
la requête PERIM permet à l’utilisateur de restreindre le périmètre géographique dans lequel sont calculés les indices de ségrégation. En l’occurrence, il s’agit de restreindre le nombre de secteurs considérées pour chacune des régions. L’utilisateur définit le nouveau périmètre à considérer à partir d’un découpage pré-établi (Ville Centre; Ville Centre + Zone Urbaine selon le Zonage en Aires Urbaines).
la requête SUBPOP permet de restreindre les présences à une sous-population. Parmi toutes les modalités des différentes variables, l’utilisateur sélectionne une sous-population (une modalité) pour laquelle il veut restreindre les calculs, par exemple les femmes. Dans ce cas, cela lui permettra de connaitre parmi la subpop des femmes la % de femmes très eduquées présentes à 14h dans un secteur X, ou de connaitre l’indice de Duncan des femmes très éduquées dans la région Y à 14h. Parce que cette requête peut conduire à raisonner sur de trop petits échantillos de personnes enquêtées par secteur.heure, une réflexion est conduite sur les informations à indiquer en NA. Cf. le doc “2023-05-23_Règles autour des agrégats du Mobiliscope et du Mobiliquest” stocké dans le git data-process/guide_admin/annexes
8.2 Dépôts gitlab et architecture des services
Le Mobiliquest utilise deux dépôts git (librement accessibles) :
https://gitlab.huma-num.fr/mobiliscope/mobiliquestt
Il s’agit du dépôt gitlab dédié au service Mobiliquest. L’API Mobiliquest qui permet de générer des requêtes à partir des données du Mobiliscope.https://gitlab.huma-num.fr/mobiliscope/services Dans ce git, on trouvera comment faire fonctionner le Mobiliscope et le Mobiliquest avec des dockers et autres services, selon l’architecture présentée sur la figure ci-dessous.
architecture Mobiliquest 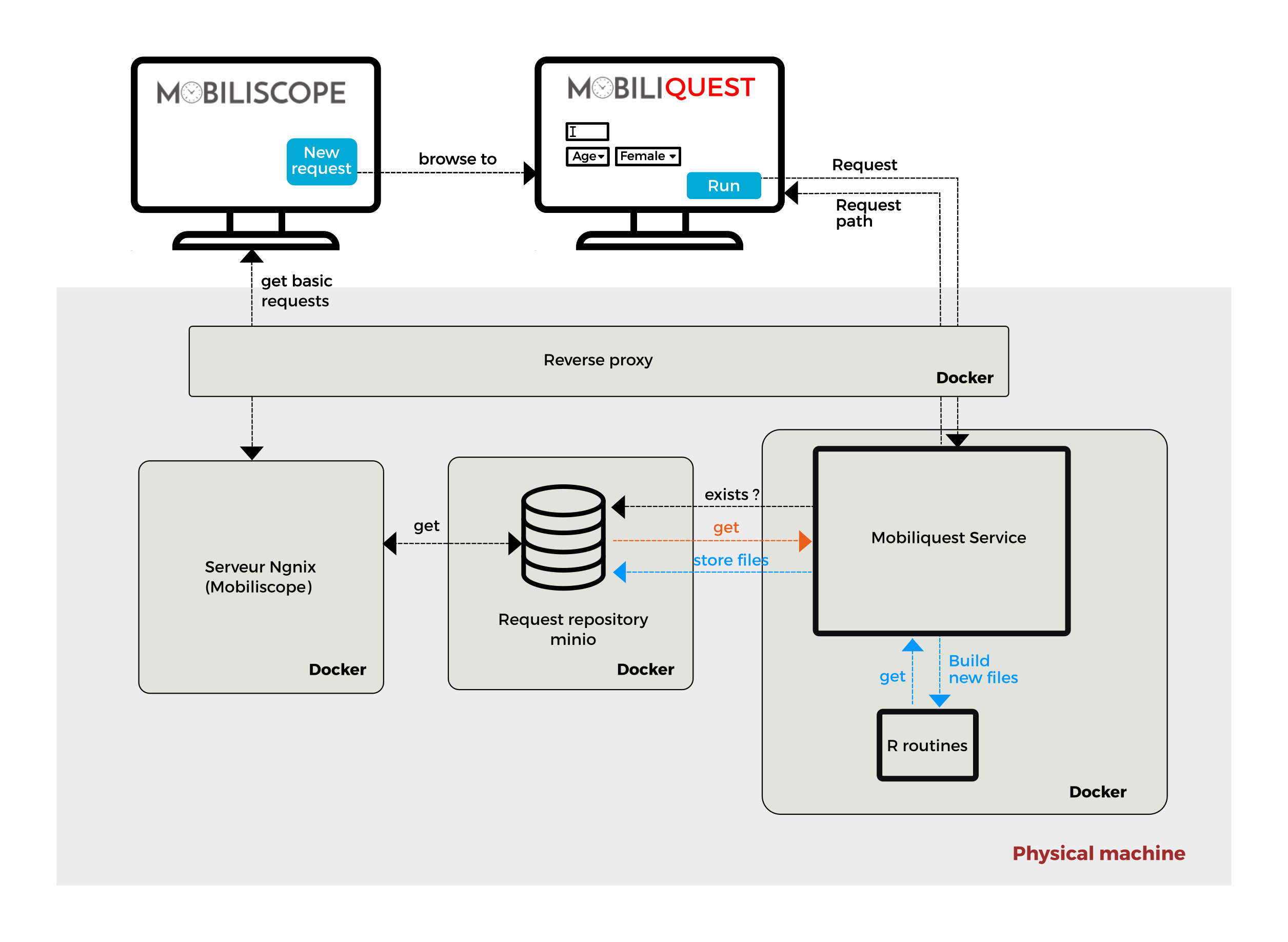
8.3 Les données - un bucket « mobiliquest » dans Minio
Le bucket « mobiliquest » du Minio contient les données utilisées dans le contexte du Mobiliquest, soit : les données en entrée (BD géographique, BD des présences utiles ainsi que deux fichiers ressources) et les données en sortie issues d’une requête effectuée pour une ville donnée et nommées avec un *hash*.
Pour le minio de test, voici ce que contient le bucket “mobiliquest”
[source] => Le répertoire où sont stockées les données en entrée du mobiliquest
[vtest]
[20230706]
[BD_geo]
[BD_presence_utile]
[ressources]
[out-data] => Le répertoire où seront stockées les données en sortie du mobiliquest
[vtest]
[20230706]
[hash1]
[hash2]
….
8.4 La fonction p2m() pour le Mobiliquest
La fonction p2m() est strictement la même pour le Mobiliscope comme pour le Mobiliquest. Toutefois, le script qui contient le code de la fonction a été dédoublé. On trouvera un script p2m_fct.R dans le git réservé à la préparation des données (https://gitlab.huma-num.fr/mobiliscope/data-process) et on trouvera le même script p2m_fct.R dans le git dédié au Mobiliquest (https://gitlab.huma-num.fr/mobiliscope/mobiliquest)
Code : https://gitlab.huma-num.fr/mobiliscope/mobiliquest/server/src/main/resources/routines/p2m_fct.R
Remarque : Même si le Mobiliquest est toujours under developpement, la fonction p2m peut déjà être utilisée par l’équipe du Mobiliscope pour sortir les données correspondant à une requête qui l’intéresse.
Pour les besoins du Mobiliquest, la fonction p2m() a été complexifiée en ajoutant deux arguments :
p2m(nomEnq, perim, subpop, cheminIn, cheminOut, env)val call = s"""\np2m("${request.study}", ${indicatorList(Perimeter())}, ${indicatorList(SubPop())}, "$inputDir", "$outputDir", 0)"""L’argument « perim » correspond au choix du périmètre sélectionné par l’utilisateur. L’argument « subpop » correspondant à la sous-population choisie par l’utilisateur. Ces arguments agissent comme des filtres préalables aux calculs sur la table des présences. Par exemple, si l’utilisateur sélectionne le périmètre « centre », la table de présence est filtrée pour ne garder que les secteurs centraux. De même pour « subpop », si l’utilisateur sélectionne la sous-population « femmes », la table de présence est filtrée pour ne garder que les présences horaires des femmes. Le calcul des indicateurs est ensuite fait à partir de la table filtrée.
L’argument « env » est dans ce contexte toujours fixé à 0.
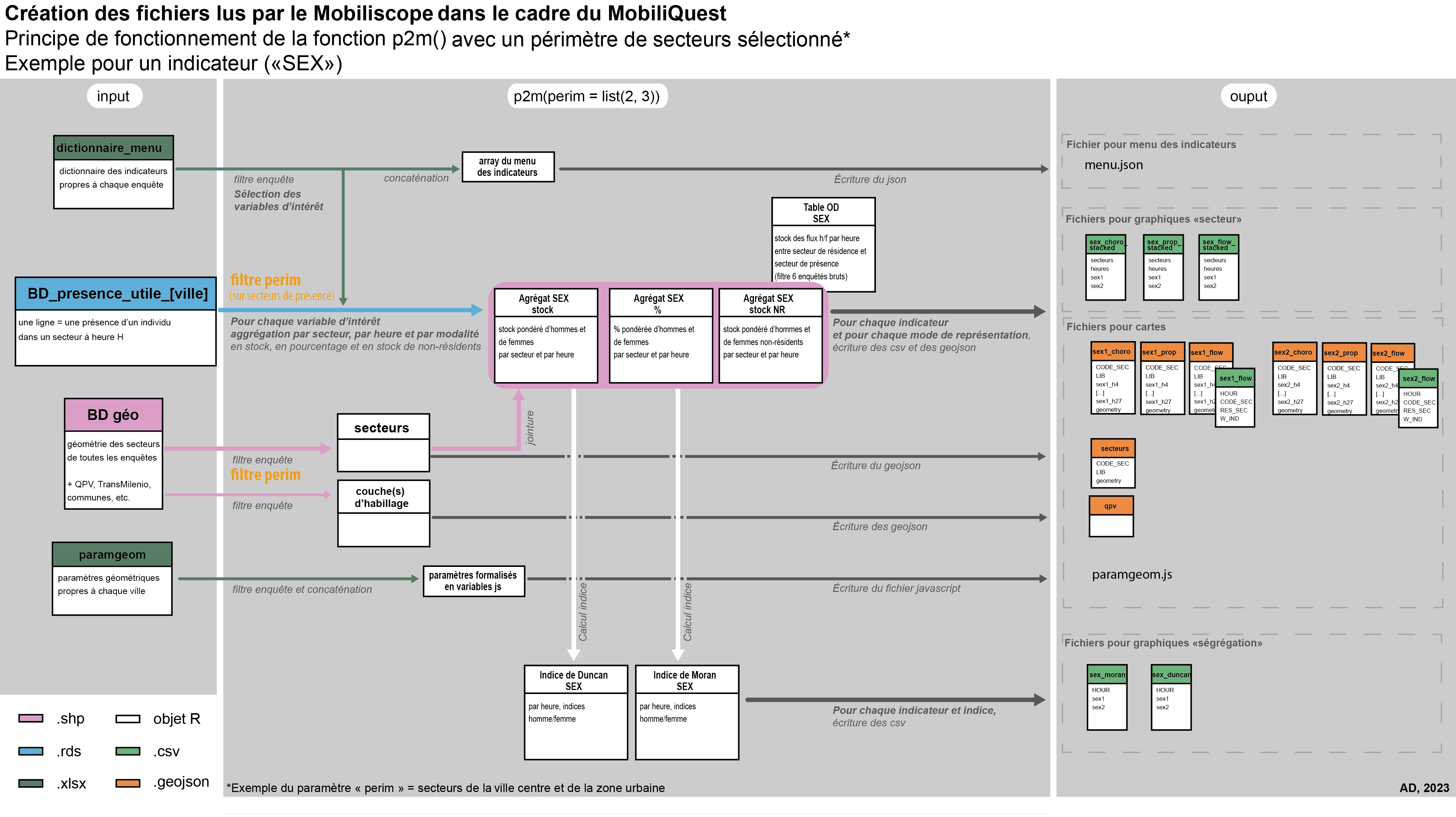
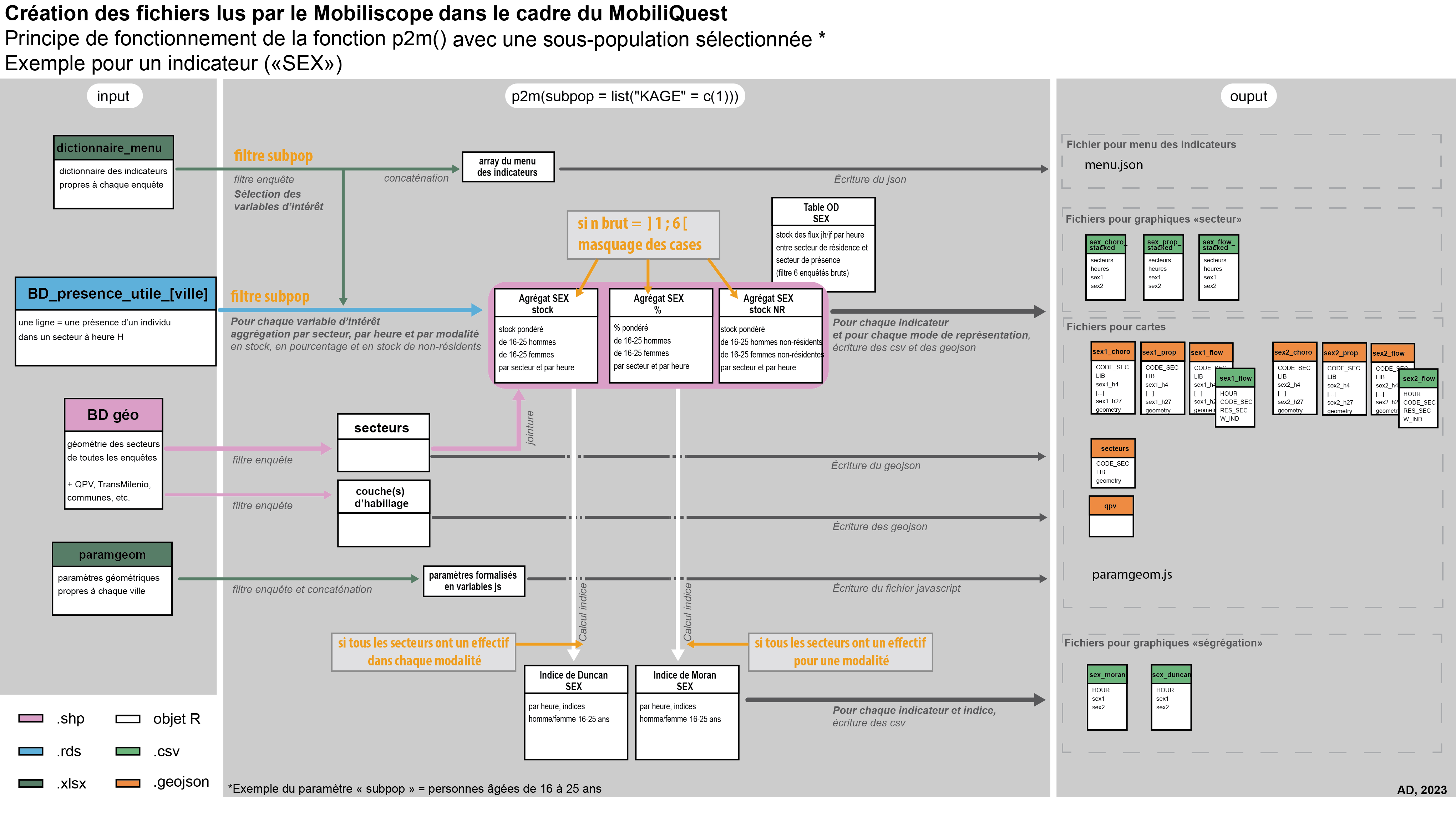
Le choix d’une sous-population entraîne l’application d’un seuil d’enquêtés bruts en deçà duquel les résultats sont masqués (Figure 20). La définition des règles de masquage est précisément formulée dans le document « 2023-05-23_Règles autour des agrégats du Mobiliscope et du Mobiliquest » (cf. data-process\guide_admin\annexes). Le codage de ces règles constitue la différence majeure entre le contexte Mobiliquest et le contexte Mobiliscope original.
Règles de masquage et gestion des NA
Cf. le doc “2023-05-23_Règles autour des agrégats du Mobiliscope et du Mobiliquest” stocké dans le git data-process/guide_admin/annexes
Pour des raisons de puissance statistique et de respect de confidentialité, le seuil de masquage est fixé à 6 répondants bruts. Lorsque le résultat brut d’un agrégat est compris entre 0 et 6 exclus, on remplace la valeur pondérée par NaN (secret primaire). Lorsqu’une seule valeur est masquée, on applique le secret secondaire : masquer la deuxième plus petite valeur afin d’empêcher la déduction de la 1ère modalité masquée par simple soustraction. Les modalités sans observation sont codées 0 et ne sont donc pas masquées.
p2m_fct.R
# Extrait de p2m(), application du secret primaire :
pvs %>%
# masquer la valeur pondérée (W) quand valeur brute (N) = ]0;6[
mutate(across(all_of(starts_with("W")),
~ case_when(get(str_replace(cur_column(), "W_IND", "N_IND")) < seuil &
get(str_replace(cur_column(), "W_IND", "N_IND")) > 0 ~ NaN,
TRUE ~ .)))Remarque : dans le code, les données masquées sont notées NaN (Not a Number) afin de les distinguer des données manquantes introduites par R lors des opérations d’agrégation et qui sont notées NA (Not Available). Ces données NA introduites par R correspondent en fait à une population nulle et sont recodées 0 par nous.
Le masquage des données agrégées de présence lorsque l’effectif n’est pas suffisant a des répercussions sur le calcul des indices de ségrégation.
L’indice de Duncan est une mesure de l’(in)égale répartition spatiale - au sein du périmètre géographique d’une enquête - entre les différents groupes de population (modalités) d’un indicateur donné. Cela n’a donc pas de sens de forcer le calcul si une modalité est manquante dans un ou plusieurs secteurs qui composent le périmètre. C’est pourquoi, si une seule modalité est manquante dans un secteur, l’indice n’est calculé pour aucune modalité. Pour observer l’évolution de la répartition des groupes au cours des 24h de la journée, l’indice est calculé 24 fois. Ainsi, pour chaque heure, l’indice de Duncan est calculé pour toutes les modalités uniquement lorsque tous les secteurs ont un effectif dans chaque modalité ; cet effectif peut être nul mais il ne doit pas être NaN.
L’indice de Moran mesure le degré de ressemblance - ou de dissemblance - sociale des secteurs géographiquement proches : est-ce que les secteurs voisins ont des caractéristiques similaires - ou différentes - du point de vue de la modalité observée ? Pour répondre à cette question, l’absence de valeur pour une modalité n’empêche pas le calcul de l’indice pour les autres modalités. En revanche, l’intégrité du périmètre doit être intacte : si, pour une modalité, un seul secteur n’a pas de valeur, on ne calcule pas l’indice. L’indice étant également calculé 24 fois, la règle se formalise de cette manière : Pour chaque heure, l’indice de Moran est calculé pour une modalité uniquement lorsque tous les secteurs ont un effectif dans cette modalité ; cet effectif peut être nul mais il ne doit pas être NaN. À noter que l’indice de Moran est calculé uniquement pour des secteurs contigus. Ainsi, un périmètre d’enquête qui contient des secteurs isolés ne correspond pas au périmètre sur lequel les indices sont calculés. C’est le cas du périmètre de Bogotá et c’est le cas de certaines enquêtes après application du filtre « perim ».
Autres fichiers en sortie :
dans le dossier « xna » : comptage des cases masquées pour chaque agrégat
stat.json : effectif brut (nombre et %) après filtrage subpop ; nombre de secteurs total et après filtrage perim
À savoir, si le paramètre « subpop » filtre 95% de la table des présences alors le processus s’arrête.
8.5 Le formulaire du Mobiliquest
Le formulaire du Mobiliquest fonctionne avec un json qui répertorie toutes les dépendances entre les champs (label et values) selon la ville et la requête (« subpop» et « perim ») sélectionnées. Ce fichier mobiliquest-form.json est construit sous R avec le script request_var_mod.R (stocké dans data-process/prepa_autres_donnees/mobiquest)
Le formulaire php est développé (en anglais) sur la branche mobiform du dépôt www : \www\english\mobiliquest.php
Pour accéder au formulaire sur la version en développement (branche mobiform): http://mobiliscope-dev/en/mobiliquest
8.6 En cas de mise à jour
8.6.1 En cas de création de nouveaux indicateurs
Exemple de l’ajout du zonage d’appartenance des secteurs canadiens (zone urbaine/périphérique).
Modifications à faire pour le formulaire du mobiliquest (cf. Section 4.3)
dans data-process/prepa_autres_donnees/mobiquest : modifier le tableur request_var_mod. Dans l’onglet « CA », ajouter les lignes correspondantes au nouvel indicateur. Dans l’onglet « perim », ajouter les lignes correspondantes aux modalités du zonage des secteurs canadiens.
modifier le script request_var_mod.R. Le code contient une exception pour les villes canadiennes qu’il faudra supprimer
faire tourner le script request_var_mod.R. En sortie, le fichier mobiliquest-form.json s’écrit directement dans le code source du Mobiliscope.
request_var_mod.R
# Extrait du code actuel perim <- read_excel("request_var_mod.xlsx", sheet = "ctry") %>% filter(ctry != "CA") %>% ## supprimer cette ligne mutate(PERIM_TYPE = case_when(cityKey %in% c('besancon', 'carcassonne') ~ "FR_BECA", ctry %in% c('CO', 'CL', 'BR') ~ "AS", TRUE ~ ctry)) %>% left_join(., perimod) %>% group_by(cityKey, ED_LIB) %>% mutate( city = paste0('{', '"label":"', ED_LIB, '",', '"value":"', cityKey, '",', map_chr(list(perim), ~paste(., collapse = ", ")), '}' ) ) %>% arrange(ED) }
8.6.2 En cas de mise à jour des données
Par exemple intégration d’une nouvelle ville…
Modifications à faire dans Minio
Dans le bucket mobiliquest du MinIO TEST d’Huma-Num
- Créer un nouveau subfolder [AAAAMMJJ] dans [source] / [vtest] pour y uploader les nouvelles bases de données : BD_geo, BD_presence_utile, ressources
- Créer un nouveau subfolder [AAAAMMJJ] dans [out-data] / [vtest] afin qu’y soient stockées les données en sortie du mobiliquest
Dans le bucket mobiliquest du MinIO PROD d’Huma-Num
- Créer un nouveau subfolder [AAAAMMJJ] dans [source] / [v4.x] pour y uploader les nouvelles bases de données : BD_geo, BD_presence_utile, ressources
- Créer un nouveau subfolder [AAAAMMJJ] dans [out-data] / [v4.x] afin qu’y soient stockées les données en sortie du mobiliquest
Aucun article correspondant